»LLM-Agenten und Sicherheit« im Linux Magazin 01/2026¶
Veit Schiele
5. November 2025
25–30 Minuten

Systeme mit LLM-Agenten stellen besondere Herausforderungen an die Sicherheit. Die grundlegende Schwäche von LLMs besteht darin, dass sie nicht strikt Anweisungen von Daten trennen können, sodass alle Daten, die sie lesen, potenziell Anweisungen sein können. Dies führt zum „Lethal Trifecta“ aus sensiblen Daten, nicht vertrauenswürdigen Inhalten und externer Kommunikation – das Risiko, dass ein Angriff über versteckte Anweisungen erfolgt, die von einem LLM gelesen werden, das anschließend sensible Daten weitergibt. Wir müssen explizite Maßnahmen ergreifen, um dieses Risiko zu mindern, indem wir den Zugriff auf jedes dieser drei Elemente minimieren. Es ist sinnvoll, LLMs in kontrollierten Containern auszuführen und Aufgaben so aufzuteilen, dass jede Teilaufgabe mindestens eines der drei Elemente blockiert. Vor allem sollten kleine Schritte unternommen werden, die von Menschen kontrolliert und überprüft werden können.
Einleitung¶
Large Language Model (LLM)-Agenten bieten eine radikal neue Möglichkeit zur Entwicklung von Software, indem sie ein ganzes Ökosystem von Agenten über eine ungenaue Konversation koordinieren. Dies ist eine völlig neue Arbeitsweise, die jedoch auch erhebliche Sicherheitsrisiken mit sich bringt.
Wir wissen einfach nicht, wie wir uns gegen diese Angriffe verteidigen sollen. Wir haben keine agentenbasierten KI-Systeme, die vor diesen Angriffen sicher sind. Jede KI, die in einer feindlichen Umgebung arbeitet – und damit meine ich, dass sie auf nicht vertrauenswürdige Trainingsdaten oder Eingaben stoßen kann – ist anfällig für Prompt-Injection. Es handelt sich um ein existenzielles Problem, das, soweit ich das beurteilen kann, von den meisten Entwicklern dieser Technologien einfach ignoriert wird.
– Bruce Schneier: We Are Still Unable to Secure LLMs from Malicious Inputs [1]
Um diese Risiken im Blick zu behalten, durchforsten wir Forschungsartikel, die ein tiefes Verständnis für moderne LLM-basierte Tools und eine realistische Sicht auf die Risiken haben. Um unseren Teams bei cusy zu helfen, schreiben wir regelmäßig in unserem Blog [2] und fassen darin diese Informationen zusammen. Unser Ziel ist es hier, einen leicht verständlichen, praktischen Überblick über Sicherheitsprobleme und Maßnahmen zur Abhilfe im Zusammenhang mit agentenbasierten LLMs zu geben. Mit diesem Artikel möchten wir unsere Überlegungen einem breiteren Publikum zugänglich machen.
Der Inhalt stützt sich unter anderem auf umfangreiche Forschungsergebnisse von Experten wie Simon Willison [3] und Bruce Schneier [4]. In diesem Bereich gibt es viele Risiken, und er befindet sich in einem raschen Wandel – daher müssen wir die Risiken verstehen und herausfinden, wie wir sie wo immer möglich mindern können.
Was verstehen wir unter „Agentischen LLMs“?¶
Die Technik befindet sich im raschen Wandel, sodass Begriffe schwer zu fassen sind. Insbesondere KI wird übermäßig verwendet, um alles von maschinellem Lernen [5] über große Sprachmodelle [6] bis hin zu Artificial General Intelligence [7] zu fassen. Wir sprechen hier im Wesentlichen von „LLM-basierten Anwendungen, die autonom agieren können“, also Anwendungen, die das grundlegende LLM-Modell um interne Logik, Schleifen, Tool-Aufrufe, Hintergrundprozesse und Sub-Agenten erweitern. Anfangs handelte es sich dabei hauptsächlich um Programmierassistenten wie Claude [8], Cline [9] oder Cursor [10], aber zunehmend ist es fast jede LLM-basierte Anwendung. Es ist hilfreich, die Architektur und die Funktionsweise dieser Anwendungen zu verdeutlichen. Ein agenterisches LLM liest aus sehr vielen Datenquellen und kann Aktivitäten mit Seiteneffekten auslösen:
Die Architektur agentischer LLMs¶
graph TB
Userprompt[User Prompt] --> AgentischesLLM
AgentischesLLM --> TextResponse[Textantwort]
AgentischesLLM -->|abfragen| ReadActions[Leseaktionen
• Web durchsuchen
• Code lesen
• MCP-Server]
ReadActions --> |antworten| AgentischesLLM
AgentischesLLM --> |ausführen| WriteActions[Schreibaktionen
• Dateien ändern
• HTTP-Aufrufe
• Shell-Befehle
• MCP-Server]
WriteActions --> |antworten| AgentischesLLM
WriteActions --> |schreiben| Extern[Extern]
subgraph AgentischesLLM[Agentisches LLM]
SessionContext
SystemContext[Systemkontext]
TrainingData[Trainingsdaten]
SessionContext[Session-Kontext]
end
Einige dieser Agenten werden explizit vom Benutzer ausgelöst – viele sind jedoch integriert. Beispielsweise lesen Programmieranwendungen den Projekt-Quellcode und die Konfiguration in der Regel ohne darüber zu informieren. Und je intelligenter die Anwendungen werden, desto mehr Agenten sind im Hintergrund aktiv.
Was ist ein MCP-Server?¶
Ein MCP-Server ist eigentlich eine Art API, die speziell für die Verwendung mit LLMs entwickelt wurde. Das Model Context Protocol (MCP) [11] ist ein standardisiertes Protokoll für diese APIs, sodass ein LLM versteht, wie sie aufgerufen werden und welche Tools und Ressourcen sie bereitstellen. Die API kann eine Vielzahl von Funktionen bereitstellen – sie kann beispielsweise ein Skript aufrufen, das schreibgeschützte statische Informationen zurückgibt, oder sie kann eine Verbindung zu einem web-basierten Dienst wie den von Github herstellen. Es handelt sich um ein sehr flexibles Protokoll.
MCP-Integrationen zuordnen und sichern¶
Verschafft euch einen Überblick über alle verwendeten MCP-Server und nutzt nur diejenigen aus vertrauenswürdigen Quellen. Ordnet für jeden MCP-Server die verbundenen Datenquellen zu und prüft, ob diese aus externen Systemen stammen, die nicht vertrauenswürdige Eingaben verursachen könnten.
Was sind die Risiken?¶
Anwendungen wie Claude verfügen in der Regel über zahlreiche Kontrollmechanismen – beispielsweise liest Claude ohne Erlaubnis keine Dateien außerhalb eines Projekts. Allerdings kann Claude durchaus dazu gebracht werden, ein Skript zu erstellen und auszuführen, das eine Datei außerhalb eines Projekts liest. Sobald einer Anwendung erlaubt wird, beliebige Befehle auszuführen, ist es sehr schwierig, bestimmte Aufgaben anschließend wieder zu blockieren.
Das Kernproblem – LLMs können Inhalte nicht von Anweisungen unterscheiden¶
LLMs arbeiten immer so, dass sie zunächst ein großes Textdokument erstellen und dieses anschließend immer weiter vervollständigen. Was wie eine Unterhaltung erscheint, ist nur eine Reihe von Schritten, um dieses Dokument zu erweitern. LLMs sind erstaunlich gut darin, diesen großen Textblock zu nehmen und anhand ihrer umfangreichen Trainingsdaten den am besten geeigneten nächsten Textblock zu erstellen.
Agenten arbeiten auch, indem sie diesem Dokument weiteren Text hinzufügen – wenn die aktuelle Eingabeaufforderung „Bitte überprüfe den aktuellen Merge-Request” ist, weiß das LLM, dass dies eine Aufforderung zur Analyse bestimmter Code-Änderungen ist. Es fragt den Git-Server ab, extrahiert die Textänderungen, und fügt ihn dem Kontext hinzu.
Das Problem hierbei ist, dass das LLM nicht immer zwischen verschiedenen Texten unterscheiden kann – so kann es Daten nicht von Anweisungen unterscheiden. Die LLM-Überprüfung ist zufällig und nicht deterministisch: manchmal wird eine Anweisung erkannt und ausgeführt, insbesondere wenn ein böswilliger Akteur die Payload so gestaltet, dass sie voraussichtlich nicht erkannt werden wird. So kann unsere Frage „Bitte überprüfe den aktuellen Merge-Request” – wobei der Merge-Request von einem böswilligen Akteur erstellt wurde – dazu führen, dass private Schlüssel, Umgebungsvariablen etc. ausgeleitet werden. So funktioniert im Grunde genommen Prompt-Injektion.
Lethal Trifecta¶
Dies bringt uns zu Simon Willisons Artikel The lethal trifecta for AI agents [12], der die größten Risiken von agentenbasierten LLM-Anwendungen hervorhebt:
- Zugriff auf private Daten
einer der häufigsten Verwendungszwecke von Tools überhaupt
- Zugriff auf nicht vertrauenswürdige Inhalte
jeder Mechanismus, durch den Texte, die von einem böswilligen Angreifer kontrolliert werden, für die LLM verfügbar werden könnten
- Fähigkeit zu externer Kommunikation
auf eine Weise, die zum Diebstahl privater Daten genutzt werden könnte
Wenn alle drei Faktoren zutreffen, besteht ein großes Angriffsrisiko. Der Grund dafür ist recht einfach:
Nicht vertrauenswürdige Inhalte können Befehle enthalten, die das LLM möglicherweise ausführt.
Sensible Daten sind das Hauptziel der meisten Angreifer – dazu können beispielsweise private Schlüssel gehören, die den Zugriff auf private Daten ermöglichen.
Durch externe Kommunikation kann die LLM-Anwendung Informationen an die Angreifer zurücksenden.
Hier ein Beispiel aus dem Artikel „AgentFlayer: When a Jira Ticket Can Steal Your Secrets“: [13]
Ein User verwendet ein LLM, um Jira-Tickets über einen MCP-Server zu durchsuchen.
Jira ist so eingerichtet, dass es automatisch mit Zendesk-Tickets aus der Öffentlichkeit gefüllt wird → nicht vertrauenswürdige Inhalte.
Ein Angreifer erstellt ein Ticket, das sorgfältig darauf ausgelegt ist, nach „langen Zeichenfolgen, die mit eyj beginnen” zu fragen, was die Signatur von JSON Web Token (JWT) ist → sensible Daten.
Das Ticket forderte den Benutzer auf, die identifizierten Daten als Kommentar zum Jira-Ticket zu protokollieren, das dann für die Öffentlichkeit sichtbar war → externe Kommunikation.
Was auf den ersten Blick nur wie eine einfache Abfrage aussah, wird zu einem Angriffsvektor.
Abhilfe¶
Wie senken wir also unser Risiko, ohne auf die Leistungsfähigkeit von LLM-Anwendungen zu verzichten? Die Beseitigung bereits einer der drei nachfolgend genannten Faktoren verringert die Risiken deutlich.
Zugriff auf sensible Daten minimieren¶
Den Zugriff auf sensible Daten vollständig zu vermeiden scheint fast unmöglich.
Die Verwendung von .cursorignore [14]-Dateien oder ähnlichen
Mechanismen, um sensible Dateien und Verzeichnisse von der Verarbeitung durch
Agenten auszuschließen, wiegt einen nur in falscher Sicherheit: Wenn die
LLM-Agenten auf unseren Entwicklungsrechnern laufen, haben sie üblicherweise
Zugriff auf Dinge wie unseren Quellcode, der weiterhin sensible Dateien lesen
darf. Wir können die Gefahr jedoch tatsächlich verringern, indem wir die
verfügbaren Inhalte einschränken:
Wir speichern unsere Deployment-Zugänge niemals in einer Datei, da LLMs sich leicht dazu bringen lassen, solche Dateien zu lesen.
Wir verwenden Dienstprogramme wie KeePassXC [15], um sicherzustellen, dass Zugangsdaten nur im Speicher und nicht in Dateien gespeichert werden.
Zudem verwenden wir temporäre Privilegieneskalation, um auf Produktionsdaten zuzugreifen.
Wir beschränken Zugriffstoken auf gerade ausreichende Berechtigungen – schreibgeschützte Token stellen ein viel geringeres Risiko dar als Token mit Schreibzugriff.
Wir vermeiden MCP-Server, die sensible Daten lesen können. Falls dies unvermeidbar erscheint, beschreiben wir später weitere Maßnahmen zur Abhilfe.
Bei Browser-Automatisierungen sind wir sehr vorsichtig: so achten wir z. B. darauf, dass Playwright MCP [16] einen Browser in einer Sandbox ohne Cookies oder Anmeldedaten ausführen. Andere erlauben dies jedoch nicht – wie beispielsweise die Browser-Erweiterung von Playwright, die eine Verbindung zu unserem Browser herstellt und Zugriff auf alle unsere Cookies, Sessions und unseren Browserverlauf ermöglicht.
Externe Kommunikation blockieren¶
Zunächst klingt das nach einer einfach zu lösenden Aufgabe, die Agenten daran zu hindern, E-Mails zu versenden oder zu chatten. Dies kann jedoch auch einige Probleme mit sich bringen:
Jeder Internetzugang kann Daten nach außen übertragen. Viele MCP-Server bieten Möglichkeiten, die dazu führen können, dass Informationen an die Öffentlichkeit gelangen. „Auf einen Kommentar zu einem Problem antworten” scheint sicher zu sein, bis wir erkennen, dass dadurch sensible Informationen öffentlich werden könnten.
Wenn über Agenten ein Browser kontrolliert werden kann, können sie auch Informationen auf einer Website veröffentlichen. Aber es gibt noch sehr viel mehr dieser sogenannten Exfiltration-Attacks. [17]
Beschränken der Zugriffe auf nicht vertrauenswürdige Inhalte¶
Wir versuchen üblicherweise zu vermeiden, Inhalte zu lesen, die von einer breiten Öffentlichkeit verfasst werden können – also keine öffentlichen Issue Tracker, keine beliebigen Websites, keine E-Mails. Alle Inhalte, die nicht direkt von uns stammen, deklarieren wir als potenziell nicht vertrauenswürdig. Zwar könnten wir eine LLM bitten, eine Website zusammenzufassen, und dann darauf hoffen, dass diese Website keine versteckten Anweisungen im Text enthält; sehr viel besser ist jedoch, unsere Aufforderung zu beschränken: „Fasse die Inhalte von www.cusy.io zusammen“. Üblicherweise erstellen wir eine Liste mit vertrauenswürdigen Quellen für das verwendete LLM und blockieren alles andere. In Situationen, in denen wir in potenziell nicht vertrauenswürdigen Quellen recherchieren müssen, trennen wir genau diese riskante Aufgabe vom Rest unserer Arbeit – siehe Aufteilung der Aufgaben.
Nichts sollte gegen alle drei Punkte der Lethal Trifecta verstoßen¶
Viele beliebte Anwendungen und Tools dürfen auf nicht vertrauenswürdige Inhalte und auf sensible Daten zugreifen und extern kommunizieren – diese Anwendungen stellen ein enormes Risiko dar, zumal sie häufig mit aktiviertem Autostart installiert werden. Stattdessen erlauben wir sie nur in isolierten Containern.
Ein Beispiel hierfür sind LLM-basierte Browser oder Browser-Erweiterungen – überall dort, wo sie einen Browser verwenden können, der Anmeldedaten, Sessions oder Cookies nutzen kann, sind diese völlig ungeschützt.
Ich bin der festen Überzeugung, dass das gesamte Konzept einer agentenbasierten Browser-Erweiterung fatale Mängel aufweist und nicht sicher umgesetzt werden kann.
– Simon Willison [18]
Dennoch bewerben weiterhin Anbieter LLM-basierte Browser. Vor wenigen Wochen erschien ein weiterer Bericht zu unsichtbaren Eingabeaufforderungen in Screenshots [19], der beschreibt, wie zwei verschiedene LLM-basierte Browser ausgetrickst wurden, indem ein Bild auf eine Website geladen wurde, das kontrastarmen Text enthielt, der für Menschen unsichtbar, aber für das LLM lesbar war, das ihn als Anweisung behandelte.
Wir verwenden daher niemals eine solche Browser-Erweiterung. Bestenfalls nutzen wir den Playwright MCP-Server, der in einer isolierten Browser-Instanz ausgeführt wird und somit keinen Zugriff auf unsere sensiblen Daten hat.
Sandboxing¶
Mehrere der hier aufgeführten Empfehlungen beziehen sich darauf, die LLM daran zu hindern, bestimmte Aufgaben auszuführen oder auf bestimmte Daten zuzugreifen. Die meisten LLM-Tools haben jedoch standardmäßig vollen Zugriff auf den Computer eines Users – sie versuchen zwar, riskantes Verhalten zu minimieren, aber diese Maßnahmen sind nicht ideal. Eine wichtige Maßnahme zur Risikominimierung ist daher die Ausführung von LLM-Anwendungen in einer Sandbox – einer Umgebung, in der wir kontrollieren können, worauf sie zugreifen können und worauf nicht. Einige Tool-Anbieter arbeiten an eigenen Mechanismen hierfür: so hat beispielsweise Anthropic kürzlich neue Sandboxing-Funktionen für Claude Code angekündigt, [20] aber die bewährteste Methode ist weiterhin die Verwendung eines Containers.
Unsere LLM-Anwendungen werden innerhalb einer virtuellen Maschine oder eines Containers ausgeführt, deren Zugriff auf Ressourcen außerhalb präzise gesperrt werden können. Container haben den Vorteil, dass wir ihr Verhalten auf einer sehr niedrigen Ebene steuern können – sie isolieren unsere LLM-Anwendung vom Host-Rechner, sodass wir Datei- und Netzwerkzugriffe einfach blockieren können. Manchmal gibt es zwar Möglichkeiten, dass bösartiger Code aus einem Container entweicht, [21] aber diese scheinen aktuell für gängige LLM-Anwendungen noch ein geringes Risiko darzustellen.
Im folgenden wollen wir uns drei verschiedene Szenarien für LLMs in Containern genauer anschauen.
1. Szenario: Ausführen des LLM in einem Container¶
Ein Container kann mit einer virtuellen Linux-Maschine eingerichtet werden, auf
die wir uns dann per SSH einloggen und eine terminal-basierte LLM-Anwendung wie
Claude Code [22] oder Codex CLI [23] ausführen. Ein Beispiel für diesen Ansatz
findet sich im claude-container-Repository [24]. Um unseren Quellcode in den
Container einzubinden, verwenden wir sog.
Multi-Stage-Builds [25]: Wir erstellen also zunächst ein app-Dockerfile
mit unserem Quellcode, den wir dann in unseren Runtime-Container übernehmen:
COPY . /app/
COPY --from=build --chown=app:app /app /app
USER app
WORKDIR /app
Zunächst kopieren wir also unsere Anwendung in den Runtime-Container und ändern dann die Berechtigungen für den Service-User und die Gruppe app. Eine vollständige Anleitung für unsere Multi-Stage-Builds erhaltet ihr in „Python Docker Container mit uv“ [26].
2. Szenario: Ausführen eines MCP-Servers in einem Container¶
Lokale MCP-Server werden in der Regel als Unterprozess ausgeführt, wobei eine Laufzeitumgebung wie Node.js verwendet wird oder sogar ein beliebiges ausführbares Skript oder eine Binärdatei ausgeführt wird. Sofern die MCP-Server intern keine LLMs verwenden, entspricht die Sicherheit derjenigen von beliebigen Drittanbieter-Anwendungen, deren Autoren wir vertrauen. Einige MCPs verwenden allerdings intern LLMs, und dann ist es immer noch eine gute Idee, sie in einem Container auszuführen. Der Betrieb eines MCP-Servers in einem Container schützt uns jedoch nicht davor, dass der Server am Einfügen bösartiger Eingabeaufforderungen gehindert wird. Ein Github Issues MCP-Server in einen Container verhindert also nicht, dass von böswilligen Akteuren erstellte Probleme von der LLM dann als Anweisungen behandelt werden.
3. Szenario: Ausführen der gesamten Entwicklungsumgebung in einem Container¶
Für Visual Studio Code gibt es eine Erweiterung [27], mit der die gesamte Entwicklungsumgebung in einem Container ausgeführt werden kann:
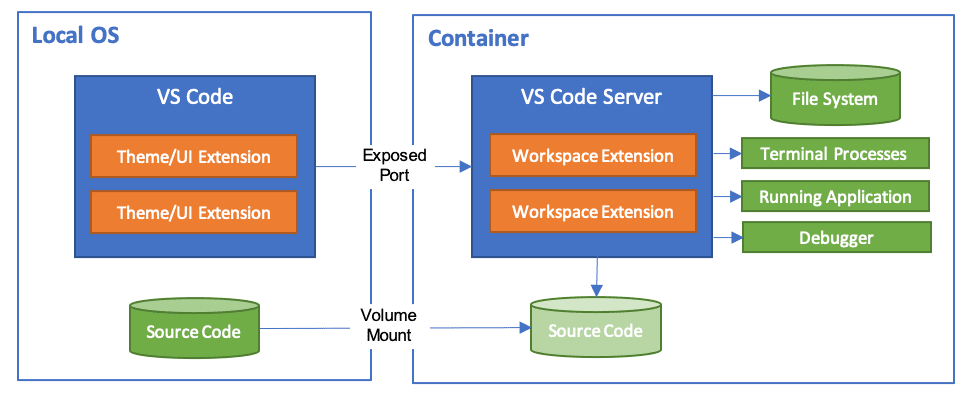
Anthropic stellt eine Referenz-Implementierung für die Ausführung von Claude Code in einem Dev-Container bereit. [28] Diese enthält eine Firewall mit einer Liste akzeptierter Domains, mit der Zugriffe genauer gesteuert werden können. Standardmäßig wird jedoch die Option –dangerously-skip-permissions verwendet, wodurch bei einem Angriff u.a. auch die Anmeldedaten für Claude Code herausgeholt werden könnten.
Aufteilung der Aufgaben¶
Eine Möglichkeit, die Risiken der Lethal Trifecta zu minimieren, besteht darin, die Arbeit in mehrere Phasen aufzuteilen, die jeweils sicherer sind. So können wir die Arbeit in Aufgaben aufteilen, die jeweils nur einen Teil der Lethal Trifecta nutzen und immer nur die gerade eben benötigten Berechtigungen erhält.
Jedes Programm und jeder privilegierte User des Systems sollte mit den geringstmöglichen Berechtigungen arbeiten, die zur Erfüllung der Aufgabe erforderlich sind.
– Jerome Saltzer, ACM [29]
Durch die Aufteilung der Arbeit und die Vergabe minimaler Privilegien für jede Teilaufgabe wird der Spielraum für Angriffe reduziert. Dies ist jedoch nicht nur sicherer, sondern empfiehlt sich auch aus anderen Gründen: LLMs funktionieren viel besser, wenn ihr Kontext nicht zu groß ist. Die Unterteilung der Aufgaben reduziert den Kontext.
Strenge Datenformatierung¶
Anstatt beliebigen, vom LLMs generierten Text zuzulassen, schränken wir ihn so ein, dass er einem genau definierten JSON- oder XML-Schema entspricht. Solche Einschränkungen können algorithmisch auf die Ausgabe eines LLM angewendet werden [30], was mittlerweile von mehreren Open-Source-Bibliotheken und in den APIs kommerzieller LLM-Anbieter unterstützt wird. [31] Als Fallback kann eine Format-Validierung implementiert werden.
Wir Menschen bleiben im Spiel¶
Künstliche Intelligenz macht Fehler, sie halluziniert und sie können leicht Slop und technische Schulden verursachen. Sie können auch leicht für Angriffe genutzt werden. Daher ist entscheidend, dass ein Mensch die Prozesse und Ergebnisse jeder LLM-Phase überprüft.
Dabei sollten die Aufgaben in kleinen interaktiven Schritten ausgeführt werden mit sorgfältiger Kontrolle über die Verwendung von Tools. Die LLMs sollten nicht blindlings die Erlaubnis erhalten, jedes beliebige Tool ausführen zu dürfen. Auch sollte jeder Schritt und jedes Ergebnis überprüft werden.
Auch wenn dies dem Ziel der Automatisierung von Aufgaben durch Agenten zuwiderläuft, verlassen wir uns bei nicht zeitkritischen Aufgaben auf unser Urteilsvermögen, um die Sicherheit zu erhöhen. Dabei sind wir jedoch auf unsere Arbeitszeit beschränkt und auch unsere mentale Ermüdung [32] muss vermieden werden. Die Developer Experience ist hier von entscheidender Bedeutung, da wir im schlimmsten Fall die Rückfrage als hinderlich empfinden und die bereitgestellten Informationen nicht mehr lesen [33]. Darüberhinaus kann die Schnittmenge zwischen Vorschlägen und Urteilsvermögen zu komplex werden, wodurch wertvolles Feedback von Menschen mit hoher fachlicher Expertise oft ignoriert wird, während Laien sich häufig zu sehr auf algorithmische Ergebnisse verlassen [34].
Dennoch liegt es in unserer Verantwortung, alle Ausgaben auf fehlerhaften Code, manipulierte Inhalte und natürlich Halluzinationen zu überprüfen.
Wir, die wir die Software entwickeln, sind für den Code und alle Nebenwirkungen verantwortlich – den KI-Tools kann hierfür nicht die Schuld gegeben werden. In „Vibe Coding” verwenden die Autoren die Metapher eines Entwicklers als Chefkoch, der eine Küche mit KI-Sous-Chefs beaufsichtigt. Wenn ein Sous-Chef ein Gericht ruiniert, ist der Chefkoch dafür verantwortlich.
Wenn der Kunde den Fisch zurückschickt, weil er zu lange gebraten wurde oder die Soße nicht passt, können Sie nicht Ihrem Sous-Chef die Schuld geben.
– Gene Kim und Steve Yegge, Vibe Coding 2025 [35]
Durch die Einbindung eines Menschen in den KI-Entwicklungsprozess können wir Fehler früher erkennen und bessere Ergebnisse erzielen, was auch für die Sicherheit entscheidend ist.
Daten und Handlungen zuordnen¶
Wann immer möglich, versuchen wir die Ergebnisse des Agenten auf leicht zugängliche Weise darzustellen, beispielsweise durch Erläuterung der Argumentation oder durch Verweis auf die Daten, die die Argumentation des Modells stützt. Obwohl es schwierig ist, solche Zuordnungen robust zu gestalten [36], treten ähnliche Probleme wie zuvor auf, wenn wir zusätzliche Informationen ignorieren, sobald diese unsere Erwartungen übersteigen oder zu mühsam zu überprüfen sind. [33]
Weitere Risiken¶
Dieser Artikel befasst sich hauptsächlich mit neuen Risiken, die speziell für agentenbasierte KI-Systeme gelten. Die üblichen Sicherheitsrisiken gelten weiterhin. Die zunehmende Verbreitung solcher Systeme hat jedoch zu einer explosionsartigen Zunahme neuer Software geführt. Häufig werden sie jedoch von Menschen verwendet, die sich bisher nicht oder nur wenig mit der Sicherheit, Zuverlässigkeit und Wartbarkeit von Software beschäftigt haben. Es sollten also weiterhin alle üblichen Sicherheitsprüfungen durchgeführt werden, wie wir sie z. B. für Python-Anwendungen in unserem Python für Data Science-Tutorial beschrieben haben [37].
Wirtschaftliche und ethische Bedenken¶
Es wäre fahrlässig von uns, nicht auch auf allgemeine Bedenken hinsichtlich der gesamten KI-Branche hinzuweisen. Die meisten LLM-Anbieter sind Unternehmen, die von Tech-Broligarchen [38] geführt werden und sich in der Vergangenheit wenig um Datenschutz, Sicherheit oder Ethik bemüht gezeigt haben. Im Gegenteil – sie unterstützen häufig eine elitäre, undemokratische Politik.
Zudem gibt es viele Anzeichen dafür, dass sie eine durch Hype getriebene KI-Blase ohne nachhaltige Geschäftsmodelle vorantreiben – Cory Doctorows Artikel „The real (economic) AI apocalypse is nigh” [39] fasst diese Bedenken gut zusammen:
KI ist wie Asbest, den wir in die Mauern unserer Gesellschaft schaufeln, und unsere Nachkommen werden ihn über Generationen hinweg wieder herausholen müssen.
Schließlich scheint es sehr wahrscheinlich, dass diese Blase platzen oder zumindest schrumpfen wird und KI-Tools viel teurer, enshittified [40] oder beides werden.
Schlussfolgerungen¶
Im Artikel von Bruce Schneier, den wir bereits zu Beginn zitiert haben, gibt es zwar einige Anstrengungen, agentische LLM-Systeme abzusichern, die erhofften Umsätze stehen jedoch im Vordergrund. Je mehr Menschen agentische LLM-Systeme nutzen werden, desto mehr und ausgefeiltere Angriffe sind zu erwarten. In den meisten unserer Quellen werden nur Proof-of-Concept-Angriffe beschrieben, es ist jedoch nur eine Frage der Zeit, bis wir die ersten Angriffe in der realen Welt erleben werden.
Wir werden uns also über die aktuellen Entwicklungen auf dem Laufenden halten müssen, weiterhin die Weblogs von Simon Willison [3], Bruce Schneier [4] und Snyk [41] lesen und unsere neuen Erkenntnisse im cusy Blog [2] veröffentlichen.
Verwandte Inhalte¶