10 Jahre Innovation und Engagement¶
Veit Schiele
22. Dezember 2025
6–7 Minuten

In den vergangenen zehn Jahren hat sich die cusy GmbH von einer kleinen, kundenorientierten Firma zu einem führenden Anbieter datenschutzkonformer IT‑Lösungen für Forschung und Entwicklung entwickelt. Dabei lag der Fokus immer auf sicheren, offenen und nachhaltigen Lösungen.
Ein Jahrzehnt im Rückblick – die wichtigsten Meilensteine¶
- 2015 – Gründung und erster Meilenstein
cusy wurde gegründet, um webbasierte Entwicklungswerkzeuge für die Gesellschaft für Datenschutz und Datensicherheit (GDD e. V.) zu hosten. Personenbezogene Daten sollten ausschließlich innerhalb Deutschlands verarbeitet werden – ein Bereich, in dem es damals keine vergleichbare Komplettlösung gab. Da der Europäische Gerichtshof Ende 2015 das Safe Harbour‑Abkommen für ungültig erklärte, mussten Unternehmen ihre personenbezogenen Daten künftig in der EU verarbeiten und cusy gewann als vertrauenswürdiger Partner an Popularität.
- 2017 – Einstieg in die Forschungsinfrastruktur
Für das Fraunhofer Institut für Solarenergie (ISE) begannen wir mit der Bereitstellung einer IT‑Infrastruktur für Forschung und Entwicklung. Wir optimierten Data‑Science‑Workflows – von der Datenerfassung bis hin zur Entwicklung produktionsgerechter Software. In den Folgejahren kamen unter anderem die Humboldt Universität, die Beuth Hochschule und Springer nature hinzu.
- 2018 – Schulungen und Community
Um Forschenden die Nutzung unserer Infrastruktur zu erleichtern, boten wir Seminare und verschiedene Tutorien an:
 Python Basics Tutorial
Python Basics Tutorial Jupyter Tutorial
PyViz Tutorial
Python for Data Science Tutorial
Jupyter Tutorial
PyViz Tutorial
Python for Data Science Tutorial- 2020–2023 – Weiterentwicklung und Sicherheit
Angesichts zunehmender Angriffe auf Open‑Source‑Software-Lieferketten implementierten wir gezielte Gegenmaßnahmen. Zudem begannen wir mit der Entwicklung einer Infrastruktur für Messstationen und eingebettete Systeme, um die Data Scientists auch in diesen Bereichen zu unterstützen. Neben den Python Users Berlin (PUB) starteten wir eine Community für Data Scientists rund um unser Schulungsangebot, basierend auf den Principles of Open Scholarly Infrastructure.
Was begründete unseren Erfolg?¶
Kundenorientierung¶
Von Anfang an haben wir eng mit Forschungsprojekten zusammengearbeitet und ihnen eine komplette IT‑Forschungsplattform bereitgestellt. Diese ermöglicht, Daten digital zu erfassen, zu analysieren und visuell aufzubereiten – alles automatisiert:
- Containerisierung
Docker und Kubernetes für Paketierung und Orchestrierung
- CI/CD‑Tools
GitLab‑basierte Pipelines zum Bauen, Testen und Deployen
- Standardisierte Projektstruktur
Einheitliche Struktur von Data‑Science‑Projekten
- Deployment‑Pipeline
Automatisches Updates der Projekt-Websites mit Dashboards für Echtzeit‑Analysen
Agilität¶
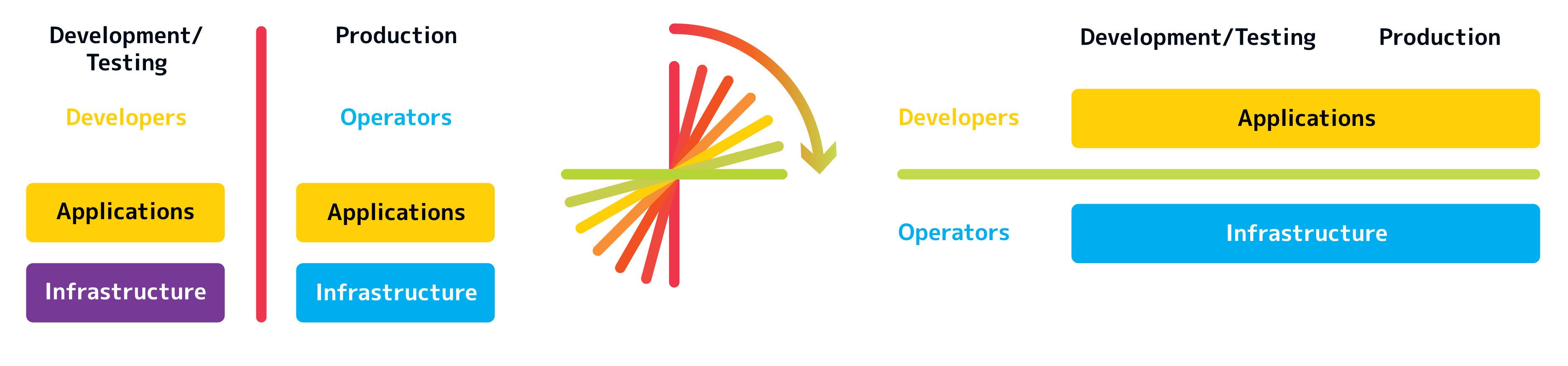
Wir haben die Silos zwischen Data Scientists, Software Engineers und Operations-Teams durch eine einheitliche IT‑Forschungsplattform aufgelöst:
- Automatisierung
Daten‑Pipelines für Aggregation, Modelltraining (→ MLOps) und sichere Forschungsumgebungen
- Versionskontrolle
Nicht nur Code, sondern auch Daten werden versioniert verwaltet, um nachvollziehbare Forschungsergebnisse zu garantieren
Community-Building¶
Durch unsere Workshops haben wir eine Community für Data Scientists aufgebaut. So könnt ihr uns z. B. vom 14.–16. April 2026 auf der PyCon DE & PyData 2026 in Darmstadt treffen.
Technologie-Fokus¶
Unsere Plattform wurde von Anfang an so gestaltet, dass sie die Trennung zwischen Softwareentwicklung und Betrieb auflöst. Die DevOps‑Idee haben wir auf Data Science übertragen – dadurch lassen sich Modelle wesentlich effizienter trainieren und Daten schneller auswerten (→ MLOps).
Highlights des Jahres 2025¶
- Erweiterung der IT‑Forschungsplattform
Integration eines leichtgewichtigen Kartenservices und barrierearmer Datenvisualisierung
- Neue Lernplattform
Ergänzung unseres Schulungsangebots um eine interaktive Lernplattform
- KI-Kurse
Kurse zu Machine Learning, Deep Learning <../our-training-courses/applied-ai-with-python und Python-Programmierung mit LLM‑Agenten
- Absicherung gegen Prompt Injections
Sicherung der IT-Forschungsplattform für den sicheren Einsatz von LLM‑Agenten
Ausblick – 2026 und darüber hinaus¶
cusy.anonymiserEin LLM‑basierter Dienst zur Erkennung und Anonymisierung personenbezogener Daten (z. B. Kreditkartennummern, Namen). Wir planen eine webbasierte Variante ab Mitte 2026 und den Einsatz zur Pseudonymisierung im Gesundheitsbereich.
cusy.extractorVerwendet LLMs, um strukturierte Informationen aus unstrukturierten Texten zu extrahieren – ideal für klinische Berichte. Der interaktiver Web‑Service wird kontextbezogene Validierungen ermöglichen.
Fazit¶
Zehn Jahre voller Herausforderungen und Erfolge haben gezeigt:
Wir unterstützen Data Scientists in einer Vielzahl von Projekten zuverlässig und nachhaltig. In den nächsten zehn Jahre setzen wir auf gemeinsames Wachstum, kontinuierliche Innovation und den Aufbau weiterführender Partnerschaften.