10 years of innovation and commitment¶
Veit Schiele
22 December 2025
5–6 minutes

Over the past ten years, cusy GmbH has grown from a small, customer-focused company into a leading provider of data protection-compliant IT solutions for research and development. The focus has always been on secure, open and sustainable solutions.
A decade in review – the most important milestones¶
- 2015 – Founding and first milestone
cusy was founded to host web-based development tools for the Society for Data Protection and Data Security (GDD e. V.). Personal data was to be processed exclusively within Germany – an area in which there was no comparable complete solution at the time. When the European Court of Justice declared the Safe Harbour Agreement invalid at the end of 2015, companies had to process their personal data within the EU in future, and cusy gained popularity as a trusted partner.
- 2017 – Entry into research infrastructure
We began providing IT infrastructure for research and development for the Fraunhofer Institute for Solar Energy (ISE). We optimised data science workflows – from data collection to the development of production-ready software. In the following years, Humboldt University, Beuth University of Applied Sciences and Springer nature, among others, were acquired.
- 2018 – Training and community
To make it easier for researchers to use our infrastructure, we offered seminars and various tutorials:
 Python Basics Tutorial
Python Basics Tutorial Jupyter Tutorial
PyViz Tutorial
Python for Data Science Tutorial
Jupyter Tutorial
PyViz Tutorial
Python for Data Science Tutorial- 2020–2023 – Further development and security
In light of increasing attacks on open source software supply chains, we implemented targeted countermeasures. We also began developing an infrastructure for measuring devices and integrated systems to support data scientists in these areas as well. In addition to Python Users Berlin (PUB), we launched a community for data scientists around our training programme, based on the Principles of Open Scholarly Infrastructure.
What was the basis for our success?¶
Customer focus¶
From the outset, we worked closely with research projects and provided them with a complete IT research platform. This enables data to be digitally captured, analysed and visually processed – all automatically:
- Containerisation
Docker and Kubernetes for packaging and orchestration
- CI/CD tools
GitLab‑based pipelines for building, testing and deploying
- Standardised project structure
Uniform structure of data science projects
- Deployment pipeline
Automatic updates of project websites with dashboards for real-time analysis
Agility¶
We have broken down the silos between data scientists, software engineers and operations teams by creating a unified IT research platform:
- Automation
Data pipelines for aggregation, model training (→ MLOps) and secure research environments
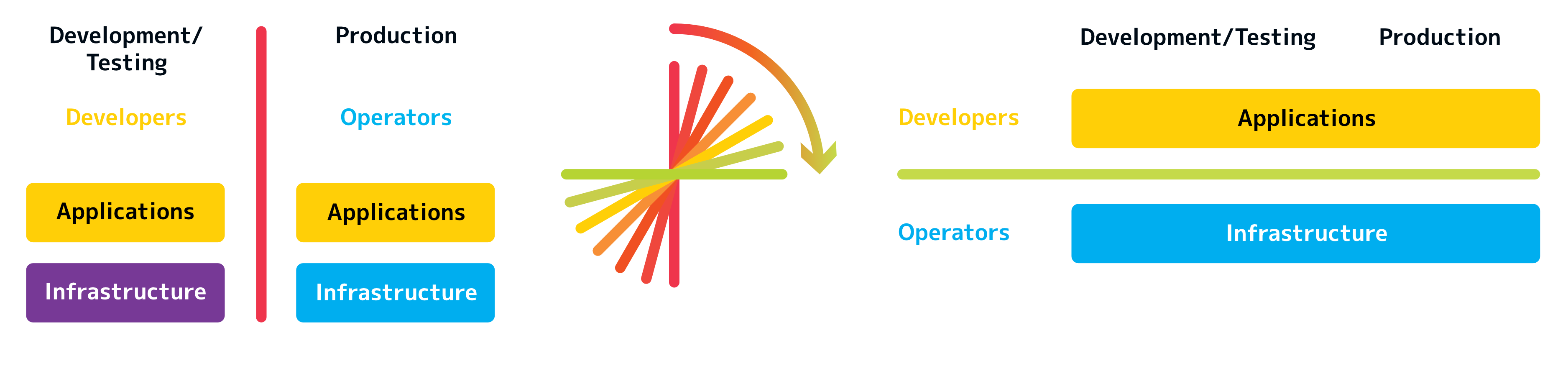
- Version control
Not only code, but also data is managed in versions to guarantee reproducible research results.
Community building¶
Through our workshops, we have built a community for data scientists. You can meet us, for example, from 14 to 16 April 2026 at PyCon DE & PyData 2026 in Darmstadt.
Technology focus¶
From the outset, our platform was designed to break down the barriers between software development and operations. We have applied the DevOps concept to data science, enabling models to be trained much more efficiently and data to be evaluated more quickly (→ MLOps).
Highlights of 2025¶
- Extension of the IT research platform
Integration of a lightweight map service and accessible data visualisation
- New learning platform
Addition of an interactive learning platform to our training offerings
- AI courses
Courses on machine learning, deep learning and Python programming with LLM agents
- Protection against prompt injections
Securing the IT research platform for the safe use of LLM agents
Outlook – 2026 and beyond¶
cusy.anonymiserAn LLM-based service for detecting and anonymising personal data (such as credit card numbers and names). We are planning a web-based version from mid-2026 and its use for pseudonymisation in the healthcare sector.
cusy.extractorUses LLMs to extract structured information from unstructured text – ideal for clinical reports. The interactive web service will enable context-sensitive validation.
Conclusion¶
Ten years full of challenges and successes have shown that
we provide reliable and sustainable support to data scientists in a wide range of projects. Over the next ten years, we will focus on joint growth, continuous innovation and the development of further partnerships.