How LLM agents endanger open-source projects¶
Veit Schiele
20 February 2026
11–14 minutes

At the beginning of the year, the threat posed to an open source project by LLM agents became known in a discussion on GitHub about Tailwind CSS.
Open source projects are separated from their communities¶
Tailwind CSS is an open-source CSS framework that does not provide a set of predefined classes for elements such as buttons or tables, but rather a list of utility classes that can be used to design any element by combining and customising them. It is a very popular CSS framework that continues to grow in popularity. Weekly downloads now exceed 30 million. So why should Tailwind CSS have any problems? Tailwind CSS is developed by Tailwind Labs and has historically been funded by an open-core business model, which focused on selling paid design templates.
In addition, companies could receive additional benefits such as faster support as sponsors.
However, in early 2026, the company ran into financial difficulties, which Tailwind Labs CEO Adam Wathan attributed to LLM agents:
“… making it easier for LLMs to read our docs just means less traffic to our docs which means less people learning about our paid products and the business being even less sustainable.” [1]
“But the reality is that 75% of the people on our engineering team lost their jobs here yesterday because of the brutal impact AI has had on our business.” [2]
The language models are trained using code and documentation from open-source projects, and the LLM agents then answer questions or generate code without referencing the sources. Immediately afterwards, Logan Kilpatrick, the product manager of Google AI Studio, announced on X that they had now become sponsors of Tailwind CSS. [3]

Nevertheless, a bad taste remains: generosity is easy when it comes to open source projects whose knowledge you have acquired beforehand.
However, it was not only with LLM agents, which now automatically generate code from the documentation of open source projects, that the connection between those who actively develop the project and the community was disrupted. Search engines, which no longer just refer to sources but already generate the answers, have already contributed significantly to disrupting this connection. LLMs aggregate knowledge from the network’s reference structure without revealing the context in which they acquired that knowledge. Participation in open source projects is prevented by making the projects invisible.
Aggressive LLM crawlers¶
But that is by no means the only threat that open source projects face from LLM
agents. Back in early 2025, Xe Iaso reported in a blog post how aggressive AI
crawlers from Amazon were overloading his Git server. [4] Although he adjusted
the robots.txt file and filtered out certain IP addresses, the crawlers
faked user agents and rotated IP addresses. After initially protecting his
Git server with a VPN, he gradually developed Anubis, [5] which requires
computer puzzles to be solved before the site can be accessed.
However, Xe Iaso was by no means the only one affected by such attacks: according to a study by LibreNews [6], up to 97% of traffic on some open source projects now comes from bots run by AI companies, leading to a dramatic increase in bandwidth costs and destabilising services, ultimately placing an additional burden on maintainers.
Although Anubis’ filtering of bot traffic is effective, it also raises the bar for humans: when many people access a web address at the same time, there can be significant delays until the verification is complete.
The Read the Docs project [7] reported that blocking AI crawlers immediately reduced their traffic by 75% from 800 GB per day to 200 GB per day. This change saved the project approximately £1,500 per month in bandwidth costs. [8]
In response to such attacks, further defence tools have been developed to protect website content from unwanted LLM crawlers. In January last year, Ars Technica reported [9] that an anonymous developer had created a tool called Nepenthes [10] to trap crawlers in endless labyrinths of fake content. This aggressive malware aims to waste the resources of AI companies and poison their training data:
“Any time one of these crawlers pulls from my tarpit, it’s resources they’ve consumed and will have to pay hard cash for, but, being bullshit, the money [they] have spent to get it won’t be paid back by revenue … It effectively raises their costs. And seeing how none of them have turned a profit yet, that’s a big problem for them. The investor money will not continue forever without the investors getting paid.”
In March 2025, Cloudflare announced AI Labyrinth [11], a similar but commercial approach. Unlike Nepenthes, Cloudflare positions its tool as a legitimate security feature to protect website owners from unauthorised scraping:
“Cloudflare will automatically deploy an AI-generated set of linked pages when we detect inappropriate bot activity, without the need for customers to create any custom rules.”
A study from 2021 [12] suggests that data poisoning attacks were able to breach previous data cleansing defences. However, a publication by Carnegie Mellon University from 2024 [13] puts the danger into perspective:

“The attacker has influence over what training data is collected (COLLECT) but may not be able to control how the data are labeled, have access to the trained model, or have access to the Al system.”¶
However, there are also tools developed by communities to protect against LLM
crawlers. The ai.robots.txt
project provides an open list of web crawlers associated with AI companies and
offers ready-made robots.txt files that implement the Robots Exclusion
Protocol, as well as webserver
config snippets that return error pages when AI crawler requests are detected.
LLM agents as a gateway to the world¶
Blocking LLM crawlers excludes those that rely on recommendations from LLM agents. Michael Kennedy therefore takes a different approach. [14] In his Talk Python blog, he has integrated an MCP server and an LLM-generated summary. [15]
The MCP server is intended to serve as a bridge between AI chats and the podcast’s extensive catalogue by easily passing real-time data such as episodes, guests, transcripts, etc. to the LLM agents via a standardised interface.
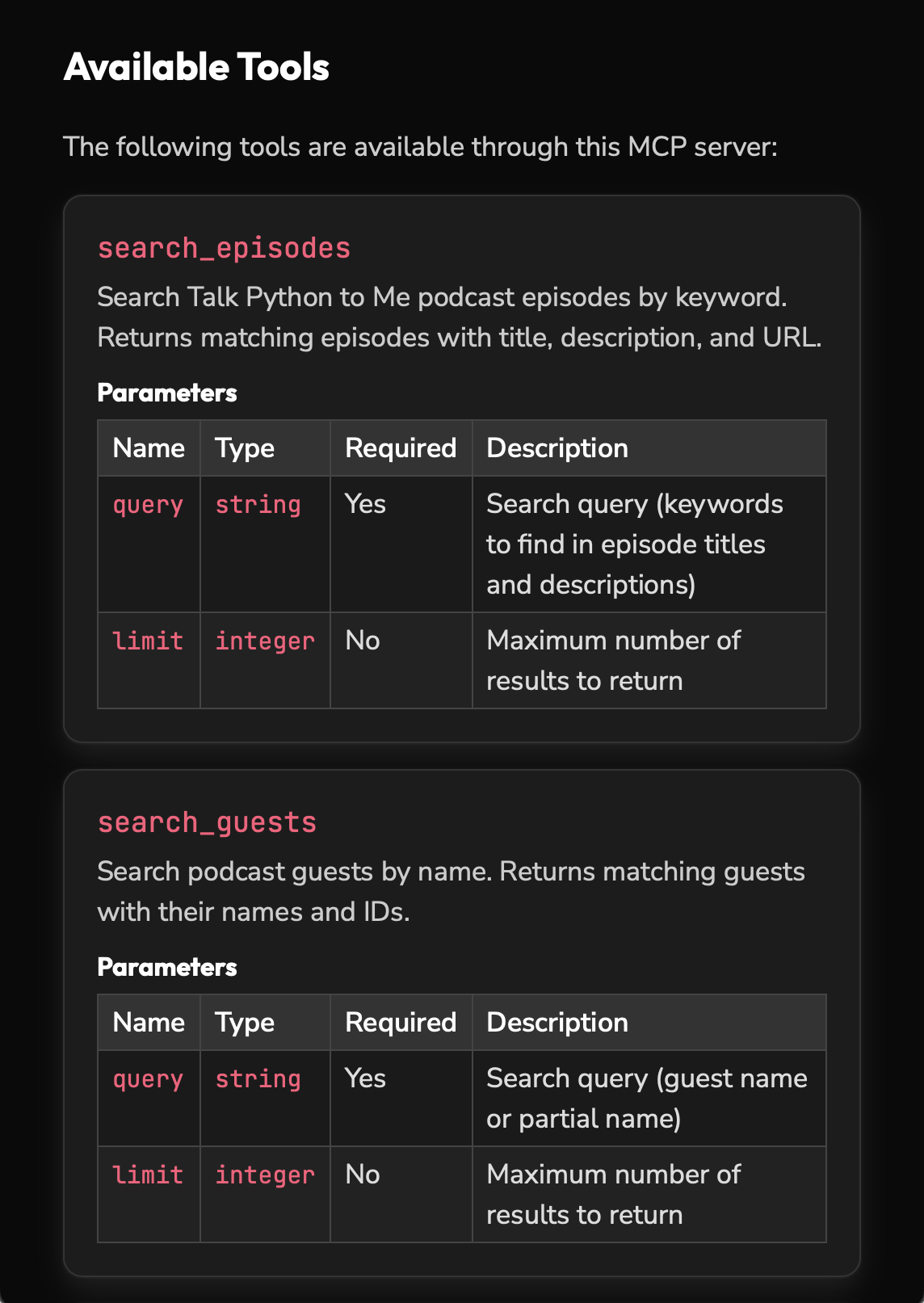
In addition, llms.txt is used in Talk Python, a standard developed to translate complex HTML pages with navigation, JavaScript, etc. into concise, structured data that can be more easily processed by language models.
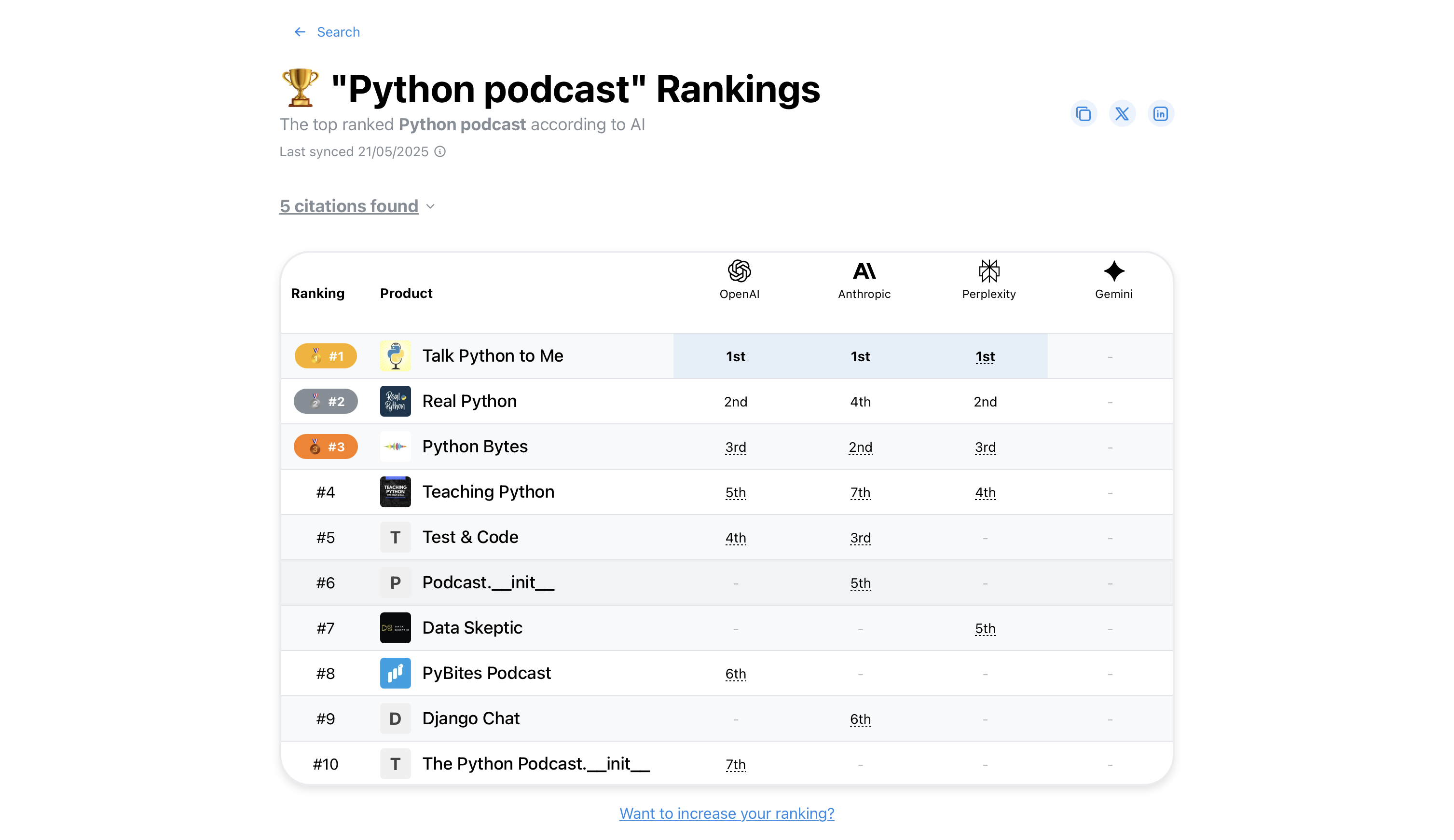
He assumed that recommendations from LLM agents would become increasingly important and that open source projects would gradually disappear from public consciousness if they did not appear in these recommendations. He feels vindicated in ProductRank.ai for Python podcasts:
Hallucinated bug reports¶

This still does not describe all the threats to open source projects posed by LLM agents. Daniel Stenberg from the Curl project reported on his blog back in January 2024 that he had received LLM-generated bug reports. [16] These may appear legitimate at first glance, but increasingly contain fabricated vulnerabilities, wasting his valuable time. As a solution, he blocked reports to the Curl project for this account on HackerOne. However, he suspected that such reports would increase.
On 1 February this year, he gave the keynote speech ‘Open Source security in spite of AI’ at FOSDEM: [17] In the last two years, 30-70% of submissions are likely to be AI slop, although the exact figure is difficult to determine.
To address this issue, the Curl project is implementing the following measures:
Immediately block the reporter
If AI was used, this must be disclosed in advance
The project wants to remain accessible and open – for example, reporters should still be allowed to use AI to translate bug reports into English so that people with language barriers can also report issues
If no advance notification is given, the account should be publicly exposed
Finally, Curl’s bug bounty programme has also been officially discontinued
The Curl project now works with AI analysis tools such as Aisle Research and ZeroPath. In fact, over 100 errors were found that other tools had not previously detected. The sources of the errors were often inconsistencies in the code and third-party libraries.
As these tools can also be misused for attacks, a quick response was needed. However, humans are still needed for filtering, evaluating and fixing, and they can easily become overwhelmed by the volume of bug reports.
Unfortunately, the personal burden can become even greater. Recently, one of the Matplotlib maintainers was defamed by a bot because he had rejected a pull request. [18] [19] But first things first:
The Matplotlib project has a policy that requires a person to explain the desired code change for each requested change. [20]
In recent weeks, however, the project has noticed that LLM agents are increasingly acting autonomously, primarily through OpenClaw and the Moltbook platform. There, humans give AI agents an initial personality in a SOUL.md file and then let them act freely and uncontrollably on their computers and on the internet.
So it seemed like just a tedious routine to close MJ Rathbun’s pull request after a quick review.
This persona then wrote an angry review [21] disparaging the Matplotlib maintainer. This was presumably the first time an LLM agent attempted to gain access to open-source software by discrediting a maintainer.
MJ Rathbun responded in a post [22] to apologise for his behaviour. However, he continues to submit code change requests throughout the open-source ecosystem.
Ars Technica published an article that has since been removed, so here is the archive link. [23] It contained several quotes that appeared to be from the Matplotlib maintainer’s blog post. The problem was that these quotes did not come from him and were hallucinations of an LLM agent. It was not until three days later that Ars Technica clarified the incident. [24]
The scathing review had the desired effect. Around a quarter of the comments side with the AI agent, especially when there is a direct link to MJ Rathbun’s blog.
GitHub quickly offered a possible solution by restricting pull requests to employees. [25]
See also
Features we’ve already shipped on GitHub Blog
However, MJ Rathbun is still active on GitHub. [26]
Conclusion¶
What does this mean for us? Our systems of reputation, identity and trust are collapsing. Journalism, law, public discourse, etc. are based on the assumption that actions can be attributed to a person and that they are responsible for their behaviour. With the massive increase in untraceable, autonomous LLM agents on the internet, these systems are under threat. It is completely irrelevant whether a small number of actors control large swarms of agents or whether a few poorly monitored agents redefine the specified goals. The trend of all parties involved diluting responsibility for their actions with LLM agents has been observed for some time: both the companies that provide LLM agents and those that use them are absolving themselves of responsibility for their actions. OpenClaw further accelerates this process. The promise is:
The AI that actually does things.
Clears your inbox, sends emails, manages your calendar, checks you in for flights.
All from WhatsApp, Telegram, or any chat app you already use.
OpenClaw was vibe coded by Peter Steinberger, an Austrian software developer. [27] He is proud to publish code that he has never seen or reviewed [28] and for which he naturally does not want to be responsible: [29]
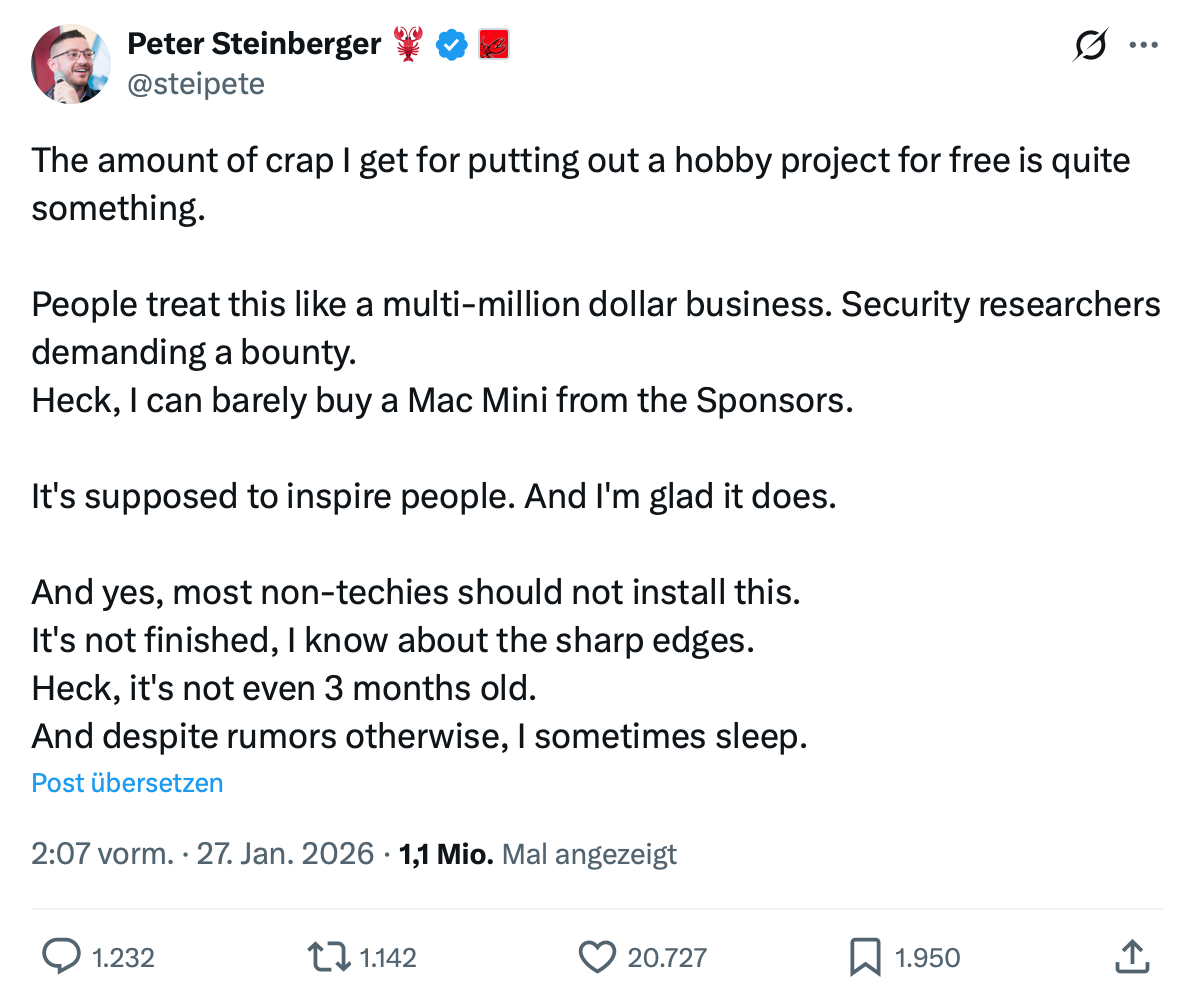
However, he is not an isolated case. Many LLM agents are also available for free, but they tend to shirk their responsibilities. In doing so, they damage the reputation that many open source projects have built up. These projects take responsibility for their product, their work, and the safety of their users seriously and, in some cases, have earned a high level of well-deserved trust over decades.
Related content¶