Agile Entwicklung & DevOps
»Nichts ist beständiger als der Wandel!«
– Heraklit von Ephesos, um 520–460 v. Chr.
cusy verbindet ein tiefes strategisches Verständnis mit Software- und Plattform-Expertise, um schnell und effektiv organisatorische Transformationen zu ermöglichen. Dies unterstützt euch bei der Vorbereitung auf zukünftige Herausforderungen. Dabei bringen wir vielfältige Erfahrungen aus verschiedenen Geschäfts- und Technologiedomänen sowie Arbeitskulturen ein. Gemeinsam können wir so die Produktorientierung eures Unternehmens und eine Plattformstrategie entwickeln, die auf datengesteuerten Entscheidungen kontinuierliche Verbesserungen ermöglicht.
Meldet euch
Ich berate euch gerne und erstelle ein passgenaues Angebot für die Beratung zu agiler Software-Entwicklung und DevOps.

Ich rufe euch auch gerne an!
Wie bessere Developer Experience die Produktivität steigert
Laut State of DevOps 2021 ist in 78 Prozent der Unternehmen die Umsetzung von DevOps auf mittlerem Niveau ins Stocken geraten. Dieser Anteil ist 4 Jahren fast gleich geblieben.

Die überwiegende Mehrheit der Unternehmen steckt in der Entwicklung von DevOps auf mittlerer Ebene fest. In der Studie wurde die mittlere Ebene in drei Kategorien unterteilt um das Phänomen genauer zu untersuchen.
Wenig überraschend ist, dass Unternehmen, die in der DevOps-Umsetzung schon weit vorangeschritten sind, auch die meisten Abläufe automatisiert haben. In diesen Unternehmen ist auch der Top-Down-Zuspruch für den Bottom-Up-Wandel am größten (→ Top-down und Bottom-up):

Weniger als 2 Prozent der Angestellten hochentwickelter Unternehmen berichten von Widerstand gegen DevOps auf Führungsebene und auch bei den mittel entwickelten Unternehmen sind es nur 3 Prozent. In ihnen geben jedoch nur 30 Prozent an, dass DevOps aktiv gefördert wird, verglichen mit 60 Prozent der hochentwickelten Unternehmen.
Eine Definition von DevOps lässt die Gründe erahnen, weswegen viele Unternehmen bei der Umsetzung steckenbleiben:
»DevOps ist die Philosophie der Vereinheitlichung von Entwicklung und Betrieb auf den Ebenen Kultur, Praxis und Tools, um eine schnellere und häufigere Bereitstellung von Änderungen in der Produktion zu erreichen.«
– Rob England: Define DevOps: What is DevOps?, 2014
Die Studie zeigt, dass DevOps-Tools zwar umfassend bereitgestellt werden, die praktische Umsetzung automatisierter Abläufe jedoch stockt und dem kulturellen Wandel Widerstand entgegenschlägt.
DevOps-Kultur
Ein wesentlicher Aspekt von DevOps-Kultur ist die gemeinsame Verantwortung für das System. Leicht verliert ein Entwicklungsteam das Interesse an Betrieb und Wartung, wenn es einem anderen Team zum Betrieb übergeben wird. Wenn jedoch das Entwicklungsteam die Verantwortung für den Betrieb eines Systems über die gesamte Lebensdauer teilt, kann es die Probleme des Betriebspersonals besser nachvollziehen und auch Wege zur Vereinfachung von Bereitstellung und Wartung finden, z.B. durch die Automatisierung von Bereitstellungen (→ Release, → Deploy, ) und verbessertes Monitoring (→ Metriken, → Incident Management, → Statusseite). Wenn umgekehrt das Betriebsteam die Verantwortung für ein System teilt, arbeiten sie enger mit dem Entwicklungsteam zusammen, das dann auch die betrieblichen Anforderungen besser versteht.
Um eine Kultur der geteilten Verantwortung zu unterstützen sind organisatorische Veränderungen erforderlich. Entwicklung und Betrieb sollten keine Silos sein. Für den Betrieb Verantwortliche sollten frühzeitig in das Entwicklungsteam eingebunden werden. Die Zusammenarbeit zwischen Entwicklung und Betrieb hilft bei der Zusammenarbeit. Übergaben und Freigaben entmutigen hingegen, behindern eine gemeinsame Verantwortung und fördern Schuldzuweisungen.

DevOps-Änderung
Um effektiv zusammenarbeiten zu können, müssen Entwicklungs- und Betriebsteam in der Lage sein, Entscheidungen zu treffen und Änderungen vorzunehmen. Dazu gehört Vertrauen in diese autonomen Teams, den nur dann wird sich ihr Umgang mit Risiken ändern und ein Umfeld geschaffen, das frei von Versagensängsten ist.
Um die Zusammenarbeit von Entwicklungsteam und Betriebspersonal zu fürdern und das System selbst kontinuierlich zu verbessern, ist Feedback essentiell. Dabei kann die Art des Feedbacks die Dauer und die Häufigkeit sehr unterschiedlich sein:
- Das Überprüfen der eigenen Code-Änderungen sollte sehr häufig erfolgen und daher nur wenige Sekunden benötigen
- Ob sich eine Komponente in alle anderen integrieren lässt, kann jedoch mehrere Stunden dauern und wird daher deutlich seltener ausgeführt werden.
- Auch die Überprüfung von nicht-funktionale Anforderungen wie Zeitverhalten, Ressourcenverbrauch, Wartbarkeit etc. kann auch schon mal einen ganzen Tag dauern.
- Die Antwort des Teams auf eine technische Frage sollte nicht erst nach Stunden oder gar Wochen erfolgen.
- Die Zeit, bis neue Team-Mitglieder produktiv werden, kann Wochen oder auch Monate dauern.
- Ein neuer Service sollte innerhalb weniger Tage produktiv werden können.
- Fehler in Produktivsystemen zu finden ist jedoch häufig erst nach einem oder mehreren Tagen erfolgreich.
- Eine erste Bestätigung durch die Zielgruppe, dass eine produktive Änderung angenommen wird, sollte nach wenigen Wochen möglich sein.
Dabei dürfte sich von selbst erklären, dass Feedbackschleifen häufiger durchgeführt werden wenn sie kürzer sind. Frühe und häufige Validierung wird auch die spätere Analyse und Nacharbeit reduzieren. Auch einfach zu interpretierende Feedback-Schleifen reduzieren die Aufwände erheblich.
Etsy erfasst nicht nur, ob die Verfügbarkeit und die Fehlerrate von Komponenten den eigenen Ansprüchen genügt, sondern auch in welchem Umfang eine Funktionsänderung von der Zielgruppe angenommen wird: sollte eine Änderung sich als wertlos herausstellen wird sie wieder entfernt, wodurch die technische Schulden reduziert werden können.
Developer Experience
Developer Experience (DX), die Konzepte aus der UX-Optimierung auf Erfahrungen in Entwicklungsteams anwendet, kann hier eine gute Ergänzung sein um die kulturelle Ebene besser aus Sicht des Entwicklungsteams zu erfassen. In Developer Experience: Concept and Definition unterscheiden Fabian Fagerholm und Jürgen Münch die folgenden drei Aspekte:
| Aspekt | Beschreibung | Themen |
|---|---|---|
| Wahrnehmung | Wie nehmen die Entwicklungsteams die Entwicklungsinfrastruktur wahr? |
|
| Emotion | Wie fühlen sich die Mitglieder des Entwicklungsteams bei ihrer Arbeit? |
|
| Motivation | Wie sehen die Mitglieder des Entwicklungsteams den Wert ihres Beitrags? |
|
So könnte der Tag für Mitglieder des Entwicklungsteams in einer wenig effektiven Umgebung aussehen:
- Der Tag beginnt mit einer Reihe von Problemen in der Produktion.
- Da es keine aggregierten Auswertungen gibt, wird der Fehler in verschiedenen Log-Dateien und Monitoring-Services gesucht.
- Schließlich wird das Problem im Auslagern des Arbeitsspeichers in eine Swap-Datei vermutet und das Betriebsteam um mehr Arbeitsspeicher gebeten.
- Nun ist endlich Zeit zu schauen, ob es Rückmeldungen vom QA-Team gab zu der neu implementierten Funktion.
- Dann ist auch schon das erste von mehreren Statusmeetings.
- Endlich könnte mit dem Entwickeln begonnen werden, wenn nur schon der Zugang zur erforderlichen API bereitgestellt worden wäre. Stattdessen werden nun Telefonate mit dem Team geführt, das die Zugänge für die API bereitstellt um nicht erst nach mehreren Tagen mit der Arbeit beginnen zu können.
Wir könnten noch viele weitere Blockaden aufzählen; letztendlich beenden die Mitglieder des Entwicklungsteams ihren Arbeitstag frustriert und demotiviert. Alles dauert länger als es sollte, und der Tag besteht aus nicht enden wollenden Hindernisse und Bürokratie. Die Mitglieder des Entwicklungsteams fühlen sich nicht nur ineffektiv und unproduktiv. Wenn sie diese Arbeitsweise irgendwann akzeptieren, breitet sich bei ihnen erlernte Hilflosigkeit aus.
In einer solchen Umgebung versuchen Unternehmen meist, die Produktivität zu messen und die leistungsschwächsten Team-Mitglieder zu erkennen indem sie die Anzahl der Code-Änderungen und erfolgreich bearbeiteten Tickets messen. In solchen Unternehmen werden meiner Erfahrung nach die besten Fachkräfte gehen; es gibt keinen Grund für sie, in einer ineffektiven Umgebung zu verharren, wenn innovative digitale Unternehmen nach starken technischen Talenten suchen.
Der Arbeitstag in einer hocheffektiven Arbeitsumgebung könnte hingegen so aussehen:
- Der Tag beginnt mit dem Blick auf das Projektmanagement-Tool des Teams, z.B. ein sog. Kanban-Board. Anschließend gibt es ein kurzes Standup-Meeting nach sich jedes Team-Mitglied im Klaren ist, woran es heute arbeiten wird.
- Das Team-Mitglied stellt fest, dass die Entwicklungsumgebung automatisch aktuelle Bibliotheken erhalten hat, die auch bereits in die Produktion übernommen wurden da alle CI/CD-Pipelines grün waren.
- Als nächstes werden die Änderungen in die eigene Entwicklungsumgebung übernommen und mit den ersten inkrementellen Code-Änderungen begonnen, die durch Komponententests schnell validiert werden können.
- Beim nächsten Feature wird der Zugang zur API eines Dienstes benötigt, der von einem anderen Team verantwortet wird. Der Zugang kann über ein zentrales Service-Portal beantragt werden, sich ergebende Fragen werden schnell in einem Chat-Raum beantwortet.
- Nun kann störungsfrei mehrere Stunden intensiv an dem neuen Feature gearbeitet werden.
- Nachdem das Feature implementiert und alle Komponententests bestanden wurden, wird in automatisierten Tests überprüft, ob sich die Komponente auch weiterhin in alle anderen Komponenten integriert.
- Sind alle Continuous-Integration-Pipelines grün, werden die Änderungen schrittweise für die vorgesehenen Zielgruppen in der Produktion freigegeben und dabei die Betriebskennzahlen überwacht.
Jedes Mitglied eines solchen Entwicklungsteams kann an einem Tag schrittweise Fortschritte machen und zufrieden mit dem Erreichten den Arbeitstag beenden. In einem solchen Arbeitsumfeld können die Arbeitsziele einfach und effizient erreicht werden und es gibt wenig Reibungsverluste. Die meiste Zeit verbringen die Team-Mitglieder damit, wertvolles zu schaffen. Produktiv zu sein motiviert die Mitglieder des Entwicklungsteams. Ohne Reibung haben sie Zeit, kreativ zu denken und sich einzusetzen. Hier konzentrieren sich die Unternehmen darauf, ein effektives technisches Umfeld bereitzustellen.
Meldet euch
Wir beraten euch gerne und erstellen ein passgenaues Angebot für eine gelingende DevOps-Transformation.
Ich rufe euch auch gerne zurück!
Software-Reviews – rechtfertigt hochwertige Software höhere Kosten?
Welchen Nutzen haben Software-Reviews?
Software-Reviews führen zu deutlich weniger Fehlern. Laut einer Untersuchung an 12-Tsd. Projekten durch Capers Jones [1] reduzieren sich diese
- bei Requirements Reviews um 20–50%
- bei Top-level Design Reviews um 30–60%
- bei detaillierten funktionellen Design Reviews um 30–65%
- bei detaillierten logischen Design Reviews um 35–75%
Die Studie kommt zu dem Ergebnis:
Schlechte Code-Qualität ist bis zum Ende der Code-Phase billiger; danach ist hohe Qualität billiger.
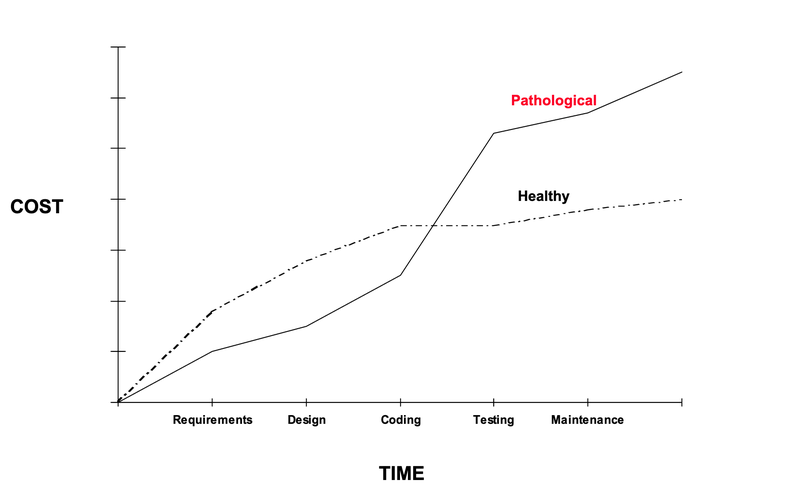
Dabei geht die Studie noch von einem klassischen Wasserfall-Modell aus von Anforderungen über Software-Architektur zunächst zu Code, dann zu Tests und Betrieb. Bei agiler Software-Entwicklung wiederholt sich dieser Prozess jedoch in vielen Zyklen, sodass wir beim Entwickeln der Software die meiste Zeit damit verbringen, die vorhandene Code-Basis zu ändern oder zu ergänzen. Daher müssen wir nicht nur die Änderungsanforderungen verstehen sondern auch den bereits vorhandenen Code. EIne bessere Code-Qualität erleichtert uns, die Funktionen unserer Anwendung zu verstehen und zu erkennen, wie die Änderungen sinnvoll umgesetzt werden. Wenn Code gut in separate Module unterteilt ist, kann ich mir viel schneller einen Überblick verschaffen als bei einer großen monolithischen Code-Basis. Weiter kann ich bei einer klaren Benennung schneller verstehen, was verschiedene Teile des Codes bewirken ohne ins Detail gehen zu müssen. Je schneller ich den Code verstehe und die gewünschte Änderung umsetzen kann, umso weniger Zeit benötige ich für die Umsetzung. Verschärfend kommt hinzu, dass sich die Wahrscheinlichkeit erhöht, dass ich einen Fehler mache. Um solche Fehler zu finden und zu beheben geht weitere Zeit verloren. Diese zusätzlichen Zeitaufwände werden üblicherweise als technische Schulden verbucht.
Umgekehrt kann ich vielleicht einen schnellen Weg finden, um eine gewünschte Funktion bereitzustellen, die jedoch den über die vorhandenen Modulgrenzen hinausgeht. Eine solche quick and dirty-Implementierung erschwert jedoch in den kommenden Wochen und Monaten die Weiterentwicklung. Auch bei agiler Software-Entwicklung ohne angemessene Code-Qualität können die Fortschritte nur am Anfang schnell sein, je länger kein Review stattfindet umso zäher wird die Weiterentwicklung sein. In vielen Diskussionen mit erfahrenen Kolleg*innen war die Einschätzung, dass bereits nach wenigen Wochen regelmäßige Reviews und Refactorings zu einer höheren Produktivitiät führen.
Welche Review-Arten lösen welche Probleme?
Es gibt unterschiedliche Möglichkeiten ein Review durchzuführen. Diese sind abhängig vom Zeitpunkt und den Zielen des Reviews.
Die Norm IEEE 1028 [2] legt die folgenden fünf Review-Arten fest:
- Walkthroughs
- Mit dieser statischen Analysetechnik entwickeln wir Szenarien und machen Probeläufe um z.B. Anomalien in den Anforderungen sowie alternative Implementierungsmöglichkeiten zu finden. Sie dienen uns zum besseren Verständnis des Problems, sie müssen jedoch nicht zu einer Entscheidung führen.
- Technische Reviews
- Diese fachlichen Prüfungen führen wir durch, um z.B. in Diskussionen alternative Software-Architekturen zu bewerten, Fehler zu finden oder technische Probleme zu lösen und zu einer (Konsens-)Entscheidung zu kommen.
- Inspektionen
- Diese formale Review-Technik nutzen wir z.B. um schnell Widersprüche in den Anforderungen, falsche Modulzuordnungen, ähnliche Funktionen o.ä. zu finden und diese möglichst frühzeitig beseitigen zu können. Häufig führen wir solche Inspektionen beim Pair-Programming durch wodurch zusätzlich noch weniger erfahrene Entwickler*innen schnell und praktisch geschult werden.
- Audits
- Häufig erstellen wir vor der Inbetriebnahme einer Kundensoftware in den Betrieb eine Bewertung ihres Software-Produkts in Bezug auf Kriterien wie Walk-Through-Berichte, Software-Architektur, Code- und Security-Analyse sowie Testverfahren.
- Management-Reviews
- Diese systematische Bewertung von Entwicklungs- oder Beschaffungsprozessen verwenden wir um einen Überblick über den Projektfortschritt zu erhalten und mit etwaigen Zeitplänen abzugleichen.
Kundenstimmen
»Vielen Dank für die gute Arbeit. Wir sind sehr zufrieden mit dem Ergebnis!«
– Niklas Kohlgraf, Projektmanagement, pooliestudios GmbH
Meldet euch
Lasst euch noch heute zu Software-Reviews von cusy beraten:
Ich rufe euch auch gerne zurück!
| [1] | Capers Jones: Software Quality in 2002: A Survey of the State of the Art |
| [2] | IEEE Standard for Software Reviews and Audits 1028–2008 |
Migration von Jenkins zu GitLab CI/CD
Unsere Erfahrung ist, dass Migrationen häufig sehr lange hinausgeschoben werden da sie keinen unmittelbaren Vorteil versprechen. Wenn die verwendeten Werkzeuge jedoch in die Jahre kommen und nicht mehr wirklich zu den neuen Anforderungen passen, häufen sich technische Schulden an, die ebenfalls die Weiterentwicklung gefährden.
Vorteile
Die Vorteile von GitLab CI/CD gegenüber Jenkins sind:
- Nahtlose Integration
- Das in GitLab integrierte CI/CD bietet einen vollständigen DevOps-Workflow, der sich nahtlos in das GitLab-Ökosystem einfügt.
- Bessere Sichtbarkeit
- Die bessere Integration führt auch zu mehr Transparenz über Pipelines und Projekte hinweg, sodass Teams fokusiert bleiben können.
- Niedrigere Betriebskosten
- Jenkins erfordert erhebliche Aufwände in Wartung und Konfiguration. GitLab hingegen bietet Code-Review und CI/CD in einer einzelnen Anwendungen.
Erste Schritte
Migrationen von Jenkins zu GitLab müssen jedoch nicht beängstigend sein. Viele Projekte wurden bereits von Jenkins zu GitLab CI/CD gewechselt, und es stehen etliche Hilfsmittel bereit um den Übergang zu erleichtern, z.B.:
Jenkins-Dateien in GitLab CI/CD ausführen
Eine kurzfristige Lösung, die Teams bei der Migration von Jenkins auf GitLab CI/CD verwenden können, ist die Verwendung von Docker, um eine Jenkins-Datei in GitLab CI/CD auszuführen, während nach und nach die Syntax aktualisiert wird. Dies behebt zwar nicht die externen Abhängigkeiten, bietet jedoch bereits eine bessere Integration in das GitLab-Projekt.
Auto DevOps verwenden
Möglicherweise kann Auto DevOps zum Erstellen, Testen und Bereitstellen Eurer Anwendungen verwendet werden, ohne dass eine spezielle Konfiguration erforderlich ist. Eine der aufwändigeren Aufgaben der Jenkins-Migration kann das Konvertieren der Pipelines von Groovy zu YAML sein; Auto DevOps bietet jedoch vordefinierte CI/CD-Konfigurationen, die in vielen Fällen eine passende Standard-Pipeline erstellen. Auto DevOps bietet weitere Funktionen wie Sicherheits-, Leistungs- und Codequalitätstests. Schließlich könnt ihr einfach die Vorlagen ändern wenn ihr weitere Anpassungen benötigt.
Best Practices
Fangt klein an!
Die oben angegebenen Erste Schritte erlauben Euch, inkrementelle Änderungen vorzunehmen. So könnt ihr kontinuierlich Fortschritte in eurem Migrationsprojekt erzielen.
Nutzt die Werkzeuge effektiv!
Mit Docker und Auto DevOps stehen Euch Werkzeuge zur Verfügung, die den Übergang vereinfachen.
Kommuniziert transparent und verständlich!
Haltet das Team über den Migrationsprozess auf dem Laufenden und teilt den Projektfortschritt mit. Strebt auch klare Jobnamen an und gestaltet Eure Konfiguration so, dass sie einen möglichst guten Überblick gibt. Schreibt ggf. Kommentare für Variablen und schwer verständlichen Code.
Meldet euch
Ich berate euch gerne und erstelle ein passgenaues Angebot für die Migration eurer Jenkins-Pipeline zu GitLab CI/CD.
Ich rufe euch auch gerne an!
Leuphana-Universität Lüneburg: IT-Infrastruktur für Hackathons
Was ist ein Hackathon?
Das Wort Hackathon setzt sich zusammen aus den beiden Worten Hack und Marathon. Es ist eine kollaborative IT-Veranstaltung mit dem Ziel, gemeinsam Prototypen zu spezifischen Themen oder Problemen herzustellen.
Über die thematische Ausrichtung eines Hackathons können Bezüge zu den Lebenswelten der Teilnehmer*innen hergestellt werden. Sie erfahren, wie Probleme gemeinsam mit technischen Mitteln gelöst werden können. Häufig wurden Hackathons jedoch auch veranstaltet um kreativ Lösungswege zu finden. Schließlich führen sie auch zu einer Vernetzung der Teilnehmer*innen, auch wenn diese aktuell nur online möglich ist.
Nach dem erfolgreichen Hackathon der Bundesregierung WirVsVirus u.a. zusammen mit Code for Germany und Prototype Fund haben auch andere für sich Hackathons als geeignetes Veranstaltungsformat gefunden, so beispielsweise auch das Hochschulforum Digitalisierung mit ihrem SemesterHack.
Für den Lüneburg Hackathon 2020 mit bis zu 500 Teilnehmer*innen konzipierten wir nicht nur die IT-Infrastruktur sondern auch die Event-Begleitung mit folgenden Phasen:
- Setup mit 24h
- 14-tägiger Vorlauf mit 9h
- 3-tägiger Event mit 36h
- 14-tägiger Nachlauf mit 5h
Im Wesentlichen sahen wir die drei große Herausforderungen:
- in kurzer Zeit uns eng mit den Veranstalter*innen der Leuphana-Universität Lüneburg abzustimmen
- eine einfache Integration der verwendeten IT-Komponenten:
- Jitsi als hochverfügbaren Cluster-Service bereitzustellen, mit dem die 500 Teilnehmer*innen gleichzeitig kommunizieren können
Wie läuft ein Hackathon ab?
Der typische Ablauf eines Online-Hackathons kann dann z.B. so aussehen:
- Begrüßung der Teilnehmer*innen und Kennenlernen im Mattermost Chat
- Vorstellung des Formats und Agenda des Hackathons mit Jitsi-Videokonferenz und Screensharing
- Kurze Impulsvorträge zu den wichtigsten Tools, Daten und thematischen Schwerpunkten
- Brainstorming mit GitLab Kanban-Boards
- Gruppenbildung mit jeweils eigenen Kanban-Boards, Git-Repositories, Mattermost-Channels und ggf. Entwicklungsumgebungen auf Basis von Jupyter Notebooks.
- Präsentationen mit Jitsi-Videokonferenzen und ggf. Jupyter Notebooks im Präsentationsmodus
Welche Hackathons gibt es in Deutschland?
- Jugend hackt
- Ihr Motto ist Mit Code die Welt verbessern und soll einen verantwortungsbewussten Umgang mit Technik fördern um Lösungen für gesellschaftspolitische Fragen zu finden. Es ist ein nicht-gwinnorientiertes Programm der gemeinnützigen Vereine Open Knowledge Foundation Deutschland e.V. und mediale pfade.org.
- Coding da Vinci
- Seit 2014 vernetzt Coding da Vinci technikaffine und kulturbegeisterte Communities mit deutschen Kulturinstitutionen, um offene Kulturdaten zu erhalten.
- Science Hack Day Berlin
- Der Science Hack Day Berlin wird von Freiwilligen aus den Bereichen Wissenschaft, Design, IT, Ingenieurwesen und Kommunikation organisiert.
- Wikimedia Hackathon
- Die Wikimedia Hackathons werden veranstaltet um um die technologische Infrastruktur von Wikipedia und anderen Wikimedia-Projekten, insbesondere der ihnen zugrunde liegenden MediaWiki-Plattform zu verbessern.
Falls ihr nun selbst einen Hackathon veranstalten möchtet, so kann Cusy auch euch mit der passenden IT-Infrastruktur und Support unterstützen.
Meldet euch
Ich berate euch gerne und erstelle ein passgenaues Angebot für IT-Infrastruktur und Support bei einem Hackathon.
Wir rufen euch auch gerne an!
Cusy DevOps-Toolchain as a Service in der iX extra 04/2020
Cusy wird im Extra Hosting für Entwickler der Zeitschrift iX 04/2020 besprochen. Insebsondere werden in diesem Heft zwei Entwicklertrends hervorgehoben: Microservices und DevOps. Dies sind auch Schwerpunkte unserer Arbeit, über die wir immer wieder berichten, z.B. in unserem Blog:
- Microservices
- Datenschutzkonforme Entwickler-Tools as a Service
- Die Vision von Cusy: DevOps als API.
Beim Beispiel einer DevOps-Toolchain bezieht sich der iX-Artikel dann auch direkt auf uns:
| Entwickleraufgabe | Softwaretool |
|---|---|
| Projektmanagement | Jira-Software |
| Dokumentenmanagement | Confluence |
| Versionsverwaltung | Gitblit |
| Code-Review | Gerrit |
| Testen/Deployment | Jenkins |
| Log-Management und -Analyse | Sentry |
| Helpdesk | Jira Service Desk |
| Webanalyse | Matomo |
Auch am Ende des Artikels wird Cusy noch einmal mit einem Alleinstellungsmerkmal erwähnt – die DevOps-Tools lassen sich leicht integrieren und verfügen über eine einheitliche Benutzerverwaltung:
Ganz auf Entwicklerwerkzeuge hat sich Cusy spezialisiert. Alle Tools lassen sich einzeln als virtuelle Maschinen buchen, können aber über ein integriertes LDAP-Directory zusammenarbeiten.
Sind Jupyter Notebooks produktionsreif?
In den letzten Jahren gab es einen rasanten Anstieg in der Verwendung von Jupyter Notebooks, s.a. Octoverse: Growth of Jupyter Notebooks, 2016-2019. Hierbei handelt es sich um eine von Mathematica inspirierte Anwendung, die Text, Visualisierung und Code in einem Dokument kombiniert. Jupyter-Notebooks werden von unseren Kunden häufig für das Prototyping und die Erforschung von Analysen und maschinellem Lernen verwendet. Wir haben jedoch auch gesehen, dass die wachsende Popularität auch dazu beigetragen hat, dass Jupyter-Notebooks in anderen Bereichen der Datenanalyse verwendet wird und zusätzliche Werkzeuge genutzt wurden, um mit ihnen auch umfangreiche Berechnungen durchzuführen.
Zum Erstellen von skalierbarem, wartbarem und langlebigem Produktionscode erscheinen uns Jupyter Notebooks jedoch meist ungeeignet. Zwar lassen sich mit einigen Tricks Notebooks sinnvoll versionieren und es lassen sich auch automatisierte Tests ausführen, bei komplexeren Projekten wird die Vermischung von Code, Kommentaren und Tests jedoch zum Hindernis: Jupyter Notebooks lassen sich nur unzureichend modularisieren. Zwar können Notebooks als Module importiert werden, diese Möglichkeiten sind jedoch äußerst beschränkt: so müssen die Notebooks zunächst vollständig in den Speicher geladen und ein neues Modul erstellt werden, bevor jede Zelle in diesem ausgeführt werden kann.
In der Folge kam es zum ersten Notebook-Krieg, s. The First Notebook War, der im Wesentlichen ein Konflikt zwischen Data Scientists und Software Engineers war.
Wie können die Gräben überwunden werden?
Notebooks erfreuen sich bei Data Scientists rasch wachsender Beliebtheit und werden zum De-facto-Standard für rapid Prototyping und explorative Analysen. Vor allem Netflix hat jedoch ein umfangreiches Ökosystem von zusätzlichen Tools und Services erstellt, wie z.B. Genie und Metacat. Diese Tools vereinfachen die Komplexität und unterstützen einen breiteren Anwenderkreis von Analysten über Wissenschaftler bis hin zu Informatikern. Im Allgemeinen hängt jede dieser Rollen von verschiedenen Tools und Sprachen ab. Oberflächlich betrachtet scheinen die Workflows unterschiedlich, wenn nicht komplementär zu sein. Auf einer abstrakteren Ebene jedoch haben diese Workflows mehrere überlappende Aufgaben:
- Datenexploration
tritt früh in einem Projekt auf
Dies kann das Anzeigen von Beispieldaten, die statistische Profilerstellung sowie die Datenvisualisierung umfassen
- Datenaufbereitung
iterative Aufgabe
kann das Bereinigen, Standardisieren, Transformieren, Denormalisieren und Aggregieren von Daten umfassen
- Datenvalidierung
wiederkehrende Aufgabe
kann das Anzeigen von Beispieldaten, das Ausführen von Abfragen zur statistischen Profilerstellung und aggregierten Analyse sowie das Visualisieren von Daten umfassen
- Produkterstellung
tritt spät in einem Projekt auf
Dies kann das Bereitstellen von Code für die Produktion, Schulungsmodelle und das Planen von Workflows umfassen
Ein JupyterHub kann hier schon gute Dienste leisten um diese Aufgaben möglichst einfach und überschaubar zu gestalten. Dabei ist es skalierbar und reduziert die Anzahl der Tools erheblich.
Um zu verstehen, warum Jupyter-Notebooks für uns so überzeugend sind, heben wir noch einmal ihre Kernfunktionalitäten hervor:
- Ein Messaging-Protokoll zum Prüfen und Ausführen von sprachunabhängigem Code
- Ein bearbeitbares Dateiformat zum Beschreiben und Erfassen von Code, Code-Ausgabe und Markdown-Notes
- Eine webbasierte Benutzeroberfläche zum interaktiven Schreiben und Ausführen von Code sowie zur Datenvisualisierung
Use Cases
Von unseren zahlreichen Anwendungsfällen verwenden wir Notebooks heute am häufigsten für Datenzugriffe, Parametrisierung und Workflow-Planung.
Datenzugriffe
Notebooks wurden von uns erstmals eingeführt, um Data-Science-Workflows zu unterstützen. Als die Akzeptanz zunahm, sahen wir die Möglichkeit, die Vielseitigkeit und Architektur von Jupyter-Notebooks auch für den allgemeinen Datenzugriff nutzen zu können. Mitte 2018 begannen wir damit, die Notebooks von einem Nischenprodukt zu einer universellen Datenplattform auszubauen.
Aus Sicht der Benutzer bieten Notebooks eine komfortable Oberfläche für die iterative Ausführung von Code, das Durchsuchen und Visualisieren von Daten – alles in einer einzigen Entwicklungsplattform. Aufgrund dieser Kombination aus Vielseitigkeit, Leistung und Benutzerfreundlichkeit haben wir eine schnelle Akzeptanz für viele Benutzergruppen auf der gesamten Plattform festgestellt.
Paremtrisierte Notebooks
Einhergehend mit der zunehmenden Akzeptanz haben wir weitere Funktionen für weitere Anwendungsfälle eingeführt. Aus dieser Arbeit gingen einfach parametrisierbare Notebooks hervor. Dies bot unseren Nutzern einen einfachen Mechanismus um Notizbücher als wiederverwendbare Vorlagen zu definieren.
Workflow-Planung
Als weiteren Einsatzbereich von Notebooks haben wir die Planung von Workflows entdeckt. Sie haben u.a. folgende Vorteile:
- Notebooks erlauben einerseits interaktives Arbeiten und rapid Prototyping, um anschließend fast reibungslos in den Produktivbetrieb überführt werden zu können. Evtl. werden die Notebooks modularisiert und als vertrauenswürdig gekennzeichnet.
- Ein weiterer Vorteil von Notebooks sind die unterschiedlichen Kernel, sodass die sich Benutzer die jeweils passende Ausführungsumgebung auswählen können.
- Zudem sind Fehler in Notebooks einfacher nachzuvollziehen da sie bestimmten Zellen zugeordnet sind und die Ausgaben gespeichert werden können.
Logging
Um Notebooks nicht nur für Rapid Prototyping sondern auch dauerhaft produktiv verwenden zu können, müssen bestimmte Prozesseereignisse protokolliert werden, sodass z.B. Fehler einfacher diagnostiziert und der Gesamtprozess überwacht werden kann. Hierfür kann in IPython Notebboks das logging-Modul der Python-Standardbibliothek oder loguru verwendet werden, s.a. Jupyter-Tutorial: Logging.
Tests
Es gab schon früher einige Ansätze, mit denen sich Notebooks automatisiert testen ließen, z.B. nbval, aber erst mit ipytest wurde das Schreiben von Tests für Notebooks deutlich vereinfacht, siehe auch Jupyter-Tutorial: ipytest.
Resümee
In den letzten Jahren förderten wir die enge Zusammenarbeit von Software Engineers mit Data Scientists um zu skalierbarem, wartbarem und produktionsfähigem Code zu gelangen. Gemeinsam haben wir Lösungen gefunden, die produktionsreife Modelle auch für Machine Learning-Projekte bereitstellen können.
Microservices – Definition
Diese Dienste implementieren Geschäftsprozesse, die unabhängig und automatisiert einsetzbar sind. Die zentrale Verwaltung dieser Dienste wird auf ein Minimum reduziert und kann in unterschiedlichen Programmiersprachen geschrieben sein und unterschiedliche Speichertechnologien nutzen.
Abgrenzung gegen Monolithen
Die Idee der Microservices ist entstanden aus der Abgrenzung zu monolithischer Software, die verschiedene Geschäftsprozesse in einer Anwendung zusammenfasst. Genauer gesagt werden diese Monolithen üblicherweise in einer Schichtenarchitektur mit drei oder vier Schichten konzipiert:
- eine Benutzeroberfläche bestehend aus HTML-Seiten und Javascript, die in einem Browser dargestellt wird
- einer meist relationalen Datenbank bestehend aus vielen Tabellen
- und einer serverseitigen Anwendung die HTTP-Anfragen beantwortet, dazu fachdomänspezifische Logik ausführt und Daten aus der Datenbank aufruft und aktualisiert.
Bei einer solchen monolithischen Anwendung läuft die Logik für die Bearbeitung einer Anforderung meist in einem einzigen Prozess und für die grundlegenden Funktionen wird nur eine Programmiersprache verwendet. Die Anwendung wird dann durch Klassen, Funktionen und Namespaces aufgeteilt. Meist kann eine solche Anwendung auf dem Laptop des Entwicklers ausgeführt und getestet und eine Deployment-Pipeline verwendet werden, um sicherzustellen, dass Änderungen ordnungsgemäß getestet und in die Produktion überführt wurden. Sie können die Monolithen horizontal skalieren indem Sie viele Instanzen hinter einem Load Balancer laufen lassen.
Solche monolithischen Anwendungen wurden jahrelang von uns erfolgreich betrieben, aber sie fingen zunehmend an, uns zu frustrieren, und zwar bei den folgenden Szenarien:
- Änderungszyklen müssen aufwändig koordiniert werden, d.h. selbst wenn nur ein kleiner Teil der Anwendung geändert werden soll, muss meist der gesamte Monolith neu gebaut und in Betrieb genommen werden.
- Zudem wird es im Laufe der Zeit immer schwerer, eine gute modulare Struktur aufrechtzuerhalten, so dass bei Änderungen wirklich nur ein Modul betroffen ist.
- Schließlich führt Skalierung immer dazu, dass die gesamte Anwendung repliziert werden muss, anstatt nur diejenigen Teile zu replizieren, die tatsächlich unter Last stehen und mehr Ressourcen erfordern.

Eine monolithische Anwendung liefert alle Funktionalität in einem Prozess …
… und skaliert durch Replikation des Monolithen auf mehreren Maschinen.
Um solche Frustrationen zu vermeiden, setzen wir seit vielen Jahren Microservices-Architekturen ein, die Anwendungen in einzelne Dienste unterteilt. Diese Services sind nicht nur unabhängig voneinander implementierbar und skalierbar, sondern bieten auch feste Kontextgrenzen, so dass unterschiedliche Dienste auch in der jeweils geeigneten Programmiersprache geschrieben und von verschiedenen Teams entwickelt und betreut werden können.

Bei einer Microservices-Architektur wird jedes Funktionselement in einem separaten Service ausgeliefert …

… und skaliert durch die Verteilung dieser Dienste über Server, repliziert nach Bedarf.
Dabei erschienen uns Microservices gar nicht besonders neuartig oder innovativ – sie erinnerten uns vielmehr an eines der Designprinzipien von Unix:
Mache nur eine Sache und mache sie gut.
Dieses Designprinzip ist jedoch in monolithischen Anwendungen nicht berücksichtigt worden.
Technische Schulden
Wir entwickeln meist in kurzen Zyklen die von unseren Kunden angefragte Funktionalität. Meistens räumen wir unseren Code auch nach mehreren Zyklen auf wenn sich die Anforderungen kaum noch ändern. Manchmal jedoch muss auch der schnell entwickelte Code in die Produktion übernommen werden. Technische Schulden ist diesbezüglich eine wunderbare Metapher, die von Ward Cunningham eingeführt wurde um über solche Probleme nachzudenken. Ähnlich wie finanzielle Schulden können technische Schulden zur Überbrückung von Schwierigkeiten verwendet werden. Und ähnlich wie bei finanziellen Schulden sind bei technischen Schulden Zinsen zu bezahlen, nämlich in Form von zusätzlichen Anstrengungen um die Software weiterzuentwickeln.
Im Gegensatz zu finanziellen Schulden lassen sich technische Schulden jedoch sehr schwer beziffern. Wir wissen zwar, dass sie die Produktivität eines Teams bei der Weiterentwicklung der Software behindern, aber wir uns fehlen die Berechnungsgrundlagen, auf denen diese Schuld beziffert werden könnte.
Um technische Schulden zu beschreiben, wird meist unterschieden zwischen bewussten und versehentlich eingegangenen technischen Schulden sowie zwischen umsichtigen oder waghalsigen Schulden. Daraus ergibt sich der folgende Quadrant:
| versehentlich | überlegt | |
| umsichtig | »Nun wissen wir, wie wir es machen sollten!« | »Wir müssen jetzt liefern und mit den Konsequenzen umgehen.« |
| waghalsig | »Was ist Software-Design?« | »Wir haben keine Zeit für Software-Design!« |
Zum Weiterlesen
- Ward Cunningham: Technical Dept
- Ward Cunningham: Complexity As Debt
Cusy 2016 Jahresrückblick
DevOps als API
Anfang des Jahres sind wir unserer Vision ein gutes Stück näher gekommen. Wir nutzen eine API, mit der automatisiert VMs erstellt, konfiguriert und gelöscht werden können. Damit erhält unsere Kundschaft die Möglichkeit, ihre Infrastruktur zu programmieren. Einzelne Systeme oder ganze Cluster können mit der API auf programmatischem Wege und jederzeit reproduzierbar bereitgestellt werden. Mehr über unsere Devops-Vision erfahren Sie in Die Vision von Cusy – DevOps als API.

IT-Compliance
Da vermutlich auch Privacy Shield kein sicherer Hafen werden wird, gehen wir davon aus, dass immer mehr Unternehmen sich nach einem verlässlichen IT-Partner in Deutschland umsehen werden. Unsere Kunden sind auf zukünftige Herausforderungen, die vor allem aus der neuen Datenschutzgrundverordnung erwachsen, gut vorbereitet. Wir können Unternehmen, die ihre IT-Compliance verbessern wollen, tatkräftig unterstützen.
Fördermitgliedschaften

Mitte des Jahres sind wir Fördermitglied der Digitalen Gesellschaft geworden.
Die Digitale Gesellschaft ist ein gemeinnütziger Verein, der sich für Grundrechte und Verbraucherschutz im digitalen Raum einsetzt. Der Verein möchte die offene digitale Gesellschaft erhalten und fördern. Er kämpft gegen den Rückbau von Freiheitsrechten im Netz und engagiert sich für einen freien Wissenszugang, für mehr Transparenz und Partizipation sowie für eine kreative Entfaltung digitaler Potenziale.
Bessere Datenschutzmaßnahmen

Nachdem Cusy von Anfang an sehr viel Wert auf technische und organisatorische Datenschutzmaßnahmen für den Betrieb im Rechenzentrum legt, haben wir Mitte des Jahres nun auch mit unseren Maßnahmen für die Absicherung der Admin-Workstations die Sicherheit deutlich erhöht. Unsere Richtlinien und Checklisten hierfür veröffentlichten wir auf unserer Website.
Transparenzbericht
Kurz vor dem erstem Geburtstag der Cusy GmbH am 29. September, veröffentlichten wir unseren ersten Transparenzbericht.
Continuous Everything
Auf der Cusy-Plattform können unsere Kunden nun auch mit Jenkins ihre Anwendung automatisiert installieren und aktualisieren. Damit sind wir einer Continuous Everything-Plattform sehr viel näher gekommen. Selbstverständlich beraten wir unsere Kunden gerne, wie sie dies technisch auf der Cusy-Plattform realisieren können.
Alternative zur Google Search Appliance
Da die Google Search Appliance ihr End of Life erreicht hat, haben wir uns nach Alternativen umgeschaut. Momentan testen wir einen Software-Stack u.a. mit Elasticsearch, Security für Authentifizierung, Autorisierung und Verschlüsselung sowie Watcher für Benachrichtigungen.
Im ersten Quartal 2017 werden wir unseren Kunden eine zuverlässige und leistungsstarke Alternative nach dem deutschen Datenschutz bereitstellen können.
Die Vision von Cusy: DevOps als API
DevOps: Die Hälfte des Weges ist geschafft
Nach Studien, über die Heise Developer kürzlich berichtete, arbeitet bereits die Hälfte der deutschen Entwickler nach dem DevOps-Prinzip. Als Befürworter von DevOps könnte man sich also zufrieden zurücklehnen und feststellen: die Hälfte des Weges ist bereits geschafft.
Doch dies ist nur die halbe Wahrheit. Wenn man sich anschaut, wie DevOps in vielen Unternehmen umgesetzt wird, so sieht man, dass ein Großteil der Pro-DevOps-Unternehmen bei der Umsetzung erst die Hälfte des Weges zurückgelegt hat. Zwar übernehmen Entwickler in DevOps-Teams mittlerweile Verantwortung für den Code auch im Betrieb, aber umgekehrt übernehmen noch nicht alle Sysadmins Verantwortung für die Infrastruktur auch in der Entwicklung. Häufig betreiben Entwickler-Teams immer noch eine eigene Infrastruktur für die Entwicklung, sodass die positiven Effekte des DevOps-Prinzips teilweise verfliegen.
Dass es sich bei DevOps um eine Veränderung der Kultur handelt und nicht bloß um die Nutzung einiger innovativer Werkzeuge, hat sich immer noch nicht überall herumgesprochen. Selbst viele Studien, in denen lediglich die Nutzung von bestimmten Werkzeugen wie Docker oder Puppet abgefragt wird, zeichnen ein falsches Bild von DevOps.
DevOps ist keine Werkzeugkiste, sondern eine Neuverteilung von Verantwortung im Unternehmen. In klassischen IT-Abteilungen ist die Verantwortung für die Bereiche Entwicklung/Testing und Produktion folgendermaßen verteilt.
Nicht selten befinden sich Development und Operations sogar in unterschiedlichen Abteilungen eines Unternehmens. In der DevOps-Kultur kippt die vertikale Trennung zwischen Entwicklung und Betrieb und es entsteht eine horizontale Schnittstelle.

Die Anwendungsentwickler übernehmen die Verantwortung für ihre Anwendung, unabhängig davon, ob diese sich in der Entwicklung oder in der Produktion befindet. Umgekehrt übernehmen die Systemverwalter aber auch die Verantwortung für die gesamte Infrastruktur von der Entwicklungsumgebung bis hin zur Produktivumgebung.
Der mit DevOps eintretende Paradigmenwechsel ist also im Wesentlichen einer, der die Verteilung von Verantwortung verändert und nicht einer, der nur neue Werkzeuge wie Puppet und Chef bereitstellt.
Cusy ist das Ops in DevOps
DevOps is the philosophy of unifying Development and Operations at the culture, practice, and tool levels, to achieve accelerated and more frequent deployment of changes to Production.
– Rob England www.itskeptic.org
Cusy erleichtert den Wechsel von der klassischen IT-Organisation zu agilen DevOps-Strukturen. Cusy übernimmt als Dienstleister die Verantwortung für die gesamte Infrastruktur: von Entwicklung über die Testumgebung bis hin zum Produktivsystem. Cusy ist das Ops in DevOps und entlastet Unternehmen von der Aufgabe, ihre Infrastruktur selbst zu pflegen. Cusy stellt Unternehmen dabei nicht nur die technische Infrastruktur zur Verfügung, sondern die komplette Entwicklungs- und Betriebsumgebung einschließlich aller benötigten Werkzeuge.
Anwendungsentwickler können sich dank Cusy bereits heute voll und ganz auf ihre Entwicklung konzentrieren. Sie müssen sich nicht um die Wartung und Pflege der notwendigen Entwicklungswerkzeuge wie Projektmanagement, Dokumentenmanagement, Versionsverwaltung kümmern.
Darüberhinaus stellt die Cusy-Plattform auch Werkzeuge für das Testen und die Produktion bereit wie Continuous Integration und eine Log-Management & Analyse bereit.
Und schließlich bietet Cusy auch Werkzeuge für Marketing und Support wie Webanalyse und Helpdesk.
Neben allen erforderlichen Werkzeugen stellt Cusy auch VMs für den Betrieb von Anwendungen bereit, die ein einfaches Continuous Delivery mit GitLab erlauben. Hierfür stellt Cusy eine API zum Erstellen, Ändern und Löschen von VMs bereitstellen. Damit ist die Vision von Cusy Wirklichkeit geworden: DevOps als API.